{"title":"Efficient spatio-temporal network for action recognition","authors":"Yanxiong Su, Qian Zhao","doi":"10.1007/s11554-024-01541-6","DOIUrl":null,"url":null,"abstract":"<p>The input tensor of video data includes temporal, spatial, and channel dimensions, crucial for extracting complementary spatial, temporal, and spatio-temporal features for video action recognition. To efficiently extract and integrate these features, we propose an efficient spatio-temporal module (ESTM) with three pathways dedicated to extracting spatial, temporal, and spatio-temporal features. Each pathway uses the Cross Global Average Pooling (CGAP) module to compress the current dimension, focusing features on the remaining two dimensions. This enhances feature extraction and recognition rates for complex actions. We also introduce a Motion Excitation Module (MEM) to enrich input features by transforming correlations between adjacent frames, reducing computational complexity. Finally, ESTM and MEM are seamlessly integrated into a 2D CNN, forming the efficient spatio-temporal network (ESTN), with minimal impact on network parameters and computational costs. Extensive experiments show that ESTN outperforms state-of-the-art methods on datasets like Something V1 & V2 and HMDB51, validating its effectiveness.</p>","PeriodicalId":51224,"journal":{"name":"Journal of Real-Time Image Processing","volume":"1 1","pages":""},"PeriodicalIF":4.9000,"publicationDate":"2024-08-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Real-Time Image Processing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11554-024-01541-6","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
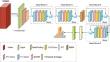
Abstract
The input tensor of video data includes temporal, spatial, and channel dimensions, crucial for extracting complementary spatial, temporal, and spatio-temporal features for video action recognition. To efficiently extract and integrate these features, we propose an efficient spatio-temporal module (ESTM) with three pathways dedicated to extracting spatial, temporal, and spatio-temporal features. Each pathway uses the Cross Global Average Pooling (CGAP) module to compress the current dimension, focusing features on the remaining two dimensions. This enhances feature extraction and recognition rates for complex actions. We also introduce a Motion Excitation Module (MEM) to enrich input features by transforming correlations between adjacent frames, reducing computational complexity. Finally, ESTM and MEM are seamlessly integrated into a 2D CNN, forming the efficient spatio-temporal network (ESTN), with minimal impact on network parameters and computational costs. Extensive experiments show that ESTN outperforms state-of-the-art methods on datasets like Something V1 & V2 and HMDB51, validating its effectiveness.
期刊介绍:
Due to rapid advancements in integrated circuit technology, the rich theoretical results that have been developed by the image and video processing research community are now being increasingly applied in practical systems to solve real-world image and video processing problems. Such systems involve constraints placed not only on their size, cost, and power consumption, but also on the timeliness of the image data processed.
Examples of such systems are mobile phones, digital still/video/cell-phone cameras, portable media players, personal digital assistants, high-definition television, video surveillance systems, industrial visual inspection systems, medical imaging devices, vision-guided autonomous robots, spectral imaging systems, and many other real-time embedded systems. In these real-time systems, strict timing requirements demand that results are available within a certain interval of time as imposed by the application.
It is often the case that an image processing algorithm is developed and proven theoretically sound, presumably with a specific application in mind, but its practical applications and the detailed steps, methodology, and trade-off analysis required to achieve its real-time performance are not fully explored, leaving these critical and usually non-trivial issues for those wishing to employ the algorithm in a real-time system.
The Journal of Real-Time Image Processing is intended to bridge the gap between the theory and practice of image processing, serving the greater community of researchers, practicing engineers, and industrial professionals who deal with designing, implementing or utilizing image processing systems which must satisfy real-time design constraints.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
