Xinyu Zhao, Jianxiang Liu, Faguo Wu, Xiao Zhang, Guojian Wang
{"title":"Uncertainty modified policy for multi-agent reinforcement learning","authors":"Xinyu Zhao, Jianxiang Liu, Faguo Wu, Xiao Zhang, Guojian Wang","doi":"10.1007/s10489-024-05811-5","DOIUrl":null,"url":null,"abstract":"<div><p>Uncertainty in the evolution of opponent behavior creates a non-stationary environment for the agent, reducing the reliability of value estimation and strategy selection while compromising security during the exploration process. Previous studies have developed various uncertainty quantification techniques and designed uncertainty-aware exploration methods for multi-agent reinforcement learning (MARL). However, existing methods have gaps in theoretical research and experimental verification of decoupling uncertainty between opponents and environment, which can decrease learning efficiency and lead to an unstable training process. Due to inaccurate opponent modeling, the agent is vulnerable to harm from opponents, which is undesirable in real-world tasks. To address these issues, this study proposes a novel uncertainty-guided safe exploration strategy for MARL that decouples the two types of uncertainty originating from the environment and opponents. Specifically, we introduce an uncertainty decoupling quantification technique based on a novel variance decomposition method for action-value functions. Furthermore, we present an uncertainty-aware policy optimization mechanism to facilitate safe exploration in MARL. Finally, we propose a new adaptive parameter scaling method to ensure efficient exploration by the agents. Theoretical analysis establishes the proposed approach’s convergence rate, and its effectiveness is demonstrated empirically. Extensive experiments on benchmark tasks spanning differential games, multi-agent particle environments, and RoboSumo validate the proposed uncertainty-guided method’s significant advantages in attaining higher scores and facilitating safe agent exploration.</p></div>","PeriodicalId":8041,"journal":{"name":"Applied Intelligence","volume":"54 22","pages":"12020 - 12034"},"PeriodicalIF":3.5000,"publicationDate":"2024-09-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Applied Intelligence","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s10489-024-05811-5","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
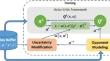
Uncertainty in the evolution of opponent behavior creates a non-stationary environment for the agent, reducing the reliability of value estimation and strategy selection while compromising security during the exploration process. Previous studies have developed various uncertainty quantification techniques and designed uncertainty-aware exploration methods for multi-agent reinforcement learning (MARL). However, existing methods have gaps in theoretical research and experimental verification of decoupling uncertainty between opponents and environment, which can decrease learning efficiency and lead to an unstable training process. Due to inaccurate opponent modeling, the agent is vulnerable to harm from opponents, which is undesirable in real-world tasks. To address these issues, this study proposes a novel uncertainty-guided safe exploration strategy for MARL that decouples the two types of uncertainty originating from the environment and opponents. Specifically, we introduce an uncertainty decoupling quantification technique based on a novel variance decomposition method for action-value functions. Furthermore, we present an uncertainty-aware policy optimization mechanism to facilitate safe exploration in MARL. Finally, we propose a new adaptive parameter scaling method to ensure efficient exploration by the agents. Theoretical analysis establishes the proposed approach’s convergence rate, and its effectiveness is demonstrated empirically. Extensive experiments on benchmark tasks spanning differential games, multi-agent particle environments, and RoboSumo validate the proposed uncertainty-guided method’s significant advantages in attaining higher scores and facilitating safe agent exploration.
期刊介绍:
With a focus on research in artificial intelligence and neural networks, this journal addresses issues involving solutions of real-life manufacturing, defense, management, government and industrial problems which are too complex to be solved through conventional approaches and require the simulation of intelligent thought processes, heuristics, applications of knowledge, and distributed and parallel processing. The integration of these multiple approaches in solving complex problems is of particular importance.
The journal presents new and original research and technological developments, addressing real and complex issues applicable to difficult problems. It provides a medium for exchanging scientific research and technological achievements accomplished by the international community.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
