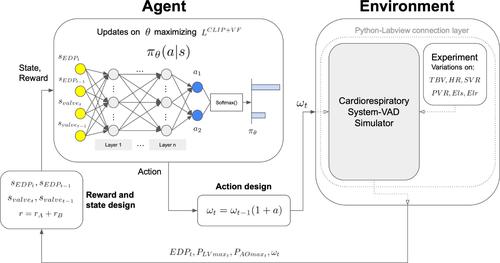
The improvement of controllers of left ventricular assist device (LVAD) technology supporting heart failure (HF) patients has enormous impact, given the high prevalence and mortality of HF in the population. The use of reinforcement learning for control applications in LVAD remains minimally explored. This work introduces a preload-based deep reinforcement learning control for LVAD based on the proximal policy optimization algorithm.
The deep reinforcement learning control is built upon data derived from a deterministic high-fidelity cardiorespiratory simulator exposed to variations of total blood volume, heart rate, systemic vascular resistance, pulmonary vascular resistance, right ventricular end-systolic elastance, and left ventricular end-systolic elastance, to replicate realistic inter- and intra-patient variability of patients with a severe HF supported by LVAD. The deep reinforcement learning control obtained in this work is trained to avoid ventricular suction and allow aortic valve opening by using left ventricular pressure signals: end-diastolic pressure, maximum pressure in the left ventricle (LV), and maximum pressure in the aorta.
The results show controller obtained in this work, compared to the constant speed LVAD alternative, assures a more stable end-diastolic volume (EDV), with a standard deviation of 5 mL and 9 mL, respectively, and a higher degree of aortic flow, with an average flow of 1.1 L/min and 0.9 L/min, respectively.
This work implements a deep reinforcement learning controller in a high-fidelity cardiorespiratory simulator, resulting in increases of flow through the aortic valve and increases of EDV stability, when compared to a constant speed LVAD strategy.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
