Jiaxi Zhao, Eline Hermans, Kia Sepassi, Christophe Tistaert, Christel A. S. Bergström, Mazen Ahmad, Per Larsson
{"title":"Effect of Data Quality and Data Quantity on the Estimation of Intrinsic Solubility: Analysis Based on a Single-Source Data Set","authors":"Jiaxi Zhao, Eline Hermans, Kia Sepassi, Christophe Tistaert, Christel A. S. Bergström, Mazen Ahmad, Per Larsson","doi":"10.1021/acs.molpharmaceut.4c00685","DOIUrl":null,"url":null,"abstract":"Aqueous solubility is one of the most important physicochemical properties of drug molecules and a major driving force for oral drug absorption. To date, the performance of in silico models for the estimation of solubility for novel chemical space is limited. To investigate possible reasons and remedies for this, the Johnson and Johnson in-house aqueous solubility data with over 40,000 compounds was leveraged. All data were generated through the same high-throughput assay, providing a unique opportunity to explore the relationship between data quality, quantity, and model estimations. Six intrinsic solubility data sets with different sizes and noise levels were generated by making use of three different approaches: (i) inclusion or exclusion of amorphous solid residue, (ii) measured or experimental log <i>D</i> to identify the intrinsic solubility, and (iii) adopting or omitting a quality check process in the data processing workflow. A random forest regressor was trained on the data sets with three different sets of descriptors calculated from RDKit, ADMET predictor, or Mordred, and the performances were evaluated with nested cross-validation as well as ten refined test sets. The models confirm, as expected, that with the same data set size, high-quality data leads to better model performance; however, also, models trained with larger data sets containing analytical variability can give equally accurate estimations compared to models trained with small, clean, and diverse data sets. However, noise introduced by including the presence of amorphous solid postsolubility measurement in the training data set cannot be overcome by increasing data size, as they are introducing a biased systematic positive error in the data set, confirming the importance of critical data review. Finally, two top-performing models were tested on the first test set from the second solubility challenge, achieving RMSE values of 0.74 and 0.72 and log <i>S</i> ± 0.5 of 46 and 48%, respectively. These results demonstrated improved performance compared to those reported in the findings of the competition, highlighting that a single-source curated data set can enhance the prediction of intrinsic solubility.","PeriodicalId":52,"journal":{"name":"Molecular Pharmaceutics","volume":"65 1","pages":""},"PeriodicalIF":4.5000,"publicationDate":"2024-09-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Molecular Pharmaceutics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1021/acs.molpharmaceut.4c00685","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICINE, RESEARCH & EXPERIMENTAL","Score":null,"Total":0}
引用次数: 0
Abstract
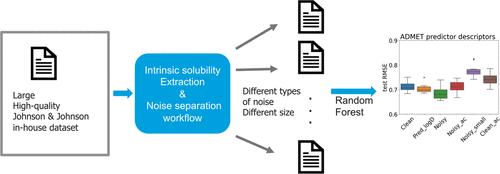
Aqueous solubility is one of the most important physicochemical properties of drug molecules and a major driving force for oral drug absorption. To date, the performance of in silico models for the estimation of solubility for novel chemical space is limited. To investigate possible reasons and remedies for this, the Johnson and Johnson in-house aqueous solubility data with over 40,000 compounds was leveraged. All data were generated through the same high-throughput assay, providing a unique opportunity to explore the relationship between data quality, quantity, and model estimations. Six intrinsic solubility data sets with different sizes and noise levels were generated by making use of three different approaches: (i) inclusion or exclusion of amorphous solid residue, (ii) measured or experimental log D to identify the intrinsic solubility, and (iii) adopting or omitting a quality check process in the data processing workflow. A random forest regressor was trained on the data sets with three different sets of descriptors calculated from RDKit, ADMET predictor, or Mordred, and the performances were evaluated with nested cross-validation as well as ten refined test sets. The models confirm, as expected, that with the same data set size, high-quality data leads to better model performance; however, also, models trained with larger data sets containing analytical variability can give equally accurate estimations compared to models trained with small, clean, and diverse data sets. However, noise introduced by including the presence of amorphous solid postsolubility measurement in the training data set cannot be overcome by increasing data size, as they are introducing a biased systematic positive error in the data set, confirming the importance of critical data review. Finally, two top-performing models were tested on the first test set from the second solubility challenge, achieving RMSE values of 0.74 and 0.72 and log S ± 0.5 of 46 and 48%, respectively. These results demonstrated improved performance compared to those reported in the findings of the competition, highlighting that a single-source curated data set can enhance the prediction of intrinsic solubility.
期刊介绍:
Molecular Pharmaceutics publishes the results of original research that contributes significantly to the molecular mechanistic understanding of drug delivery and drug delivery systems. The journal encourages contributions describing research at the interface of drug discovery and drug development.
Scientific areas within the scope of the journal include physical and pharmaceutical chemistry, biochemistry and biophysics, molecular and cellular biology, and polymer and materials science as they relate to drug and drug delivery system efficacy. Mechanistic Drug Delivery and Drug Targeting research on modulating activity and efficacy of a drug or drug product is within the scope of Molecular Pharmaceutics. Theoretical and experimental peer-reviewed research articles, communications, reviews, and perspectives are welcomed.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
