Vincenzo Guastafierro, Devin N. Corbitt, Alessandra Bressan, Bethania Fernandes, Ömer Mintemur, Francesca Magnoli, Susanna Ronchi, Stefano La Rosa, Silvia Uccella, Salvatore Lorenzo Renne
{"title":"Unveiling the risks of ChatGPT in diagnostic surgical pathologyChatGPT","authors":"Vincenzo Guastafierro, Devin N. Corbitt, Alessandra Bressan, Bethania Fernandes, Ömer Mintemur, Francesca Magnoli, Susanna Ronchi, Stefano La Rosa, Silvia Uccella, Salvatore Lorenzo Renne","doi":"10.1007/s00428-024-03918-1","DOIUrl":null,"url":null,"abstract":"<p>ChatGPT, an AI capable of processing and generating human-like language, has been studied in medical education and care, yet its potential in histopathological diagnosis remains unexplored. This study evaluates ChatGPT’s reliability in addressing pathology-related diagnostic questions across ten subspecialties and its ability to provide scientific references. We crafted five clinico-pathological scenarios per subspecialty, simulating a pathologist using ChatGPT to refine differential diagnoses. Each scenario, aligned with current diagnostic guidelines and validated by expert pathologists, was posed as open-ended or multiple-choice questions, either requesting scientific references or not. Outputs were assessed by six pathologists according to. (1) usefulness in supporting the diagnosis and (2) absolute number of errors. We used directed acyclic graphs and structural causal models to determine the effect of each scenario type, field, question modality, and pathologist evaluation. We yielded 894 evaluations. ChatGPT provided useful answers in 62.2% of cases, and 32.1% of outputs contained no errors, while the remaining had at least one error. ChatGPT provided 214 bibliographic references: 70.1% correct, 12.1% inaccurate, and 17.8% non-existing. Scenario variability had the greatest impact on ratings, and latent knowledge across fields showed minimal variation. Although ChatGPT provided useful responses in one-third of cases, the frequency of errors and variability underscores its inadequacy for routine diagnostic use and highlights the need for discretion as a support tool. Imprecise referencing also suggests caution as a self-learning tool. It is essential to recognize the irreplaceable role of human experts in synthesizing images, clinical data, and experience for the intricate task of histopathological diagnosis.</p><h3 data-test=\"abstract-sub-heading\">Graphical Abstract</h3>\n","PeriodicalId":23514,"journal":{"name":"Virchows Archiv","volume":"5 1","pages":""},"PeriodicalIF":3.1000,"publicationDate":"2024-09-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Virchows Archiv","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s00428-024-03918-1","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"PATHOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
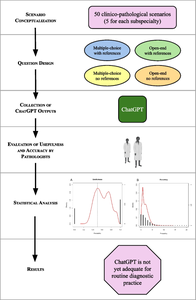
ChatGPT, an AI capable of processing and generating human-like language, has been studied in medical education and care, yet its potential in histopathological diagnosis remains unexplored. This study evaluates ChatGPT’s reliability in addressing pathology-related diagnostic questions across ten subspecialties and its ability to provide scientific references. We crafted five clinico-pathological scenarios per subspecialty, simulating a pathologist using ChatGPT to refine differential diagnoses. Each scenario, aligned with current diagnostic guidelines and validated by expert pathologists, was posed as open-ended or multiple-choice questions, either requesting scientific references or not. Outputs were assessed by six pathologists according to. (1) usefulness in supporting the diagnosis and (2) absolute number of errors. We used directed acyclic graphs and structural causal models to determine the effect of each scenario type, field, question modality, and pathologist evaluation. We yielded 894 evaluations. ChatGPT provided useful answers in 62.2% of cases, and 32.1% of outputs contained no errors, while the remaining had at least one error. ChatGPT provided 214 bibliographic references: 70.1% correct, 12.1% inaccurate, and 17.8% non-existing. Scenario variability had the greatest impact on ratings, and latent knowledge across fields showed minimal variation. Although ChatGPT provided useful responses in one-third of cases, the frequency of errors and variability underscores its inadequacy for routine diagnostic use and highlights the need for discretion as a support tool. Imprecise referencing also suggests caution as a self-learning tool. It is essential to recognize the irreplaceable role of human experts in synthesizing images, clinical data, and experience for the intricate task of histopathological diagnosis.
期刊介绍:
Manuscripts of original studies reinforcing the evidence base of modern diagnostic pathology, using immunocytochemical, molecular and ultrastructural techniques, will be welcomed. In addition, papers on critical evaluation of diagnostic criteria but also broadsheets and guidelines with a solid evidence base will be considered. Consideration will also be given to reports of work in other fields relevant to the understanding of human pathology as well as manuscripts on the application of new methods and techniques in pathology. Submission of purely experimental articles is discouraged but manuscripts on experimental work applicable to diagnostic pathology are welcomed. Biomarker studies are welcomed but need to abide by strict rules (e.g. REMARK) of adequate sample size and relevant marker choice. Single marker studies on limited patient series without validated application will as a rule not be considered. Case reports will only be considered when they provide substantial new information with an impact on understanding disease or diagnostic practice.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
