Pradnya Kamble, Prinsa R. Nagar, Kaushikkumar A. Bhakhar, Prabha Garg, M. Elizabeth Sobhia, Srivatsava Naidu, Prasad V. Bharatam
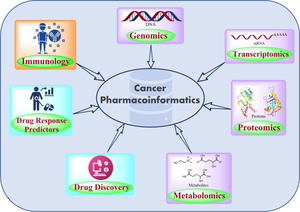
{"title":"Cancer pharmacoinformatics: Databases and analytical tools","authors":"Pradnya Kamble, Prinsa R. Nagar, Kaushikkumar A. Bhakhar, Prabha Garg, M. Elizabeth Sobhia, Srivatsava Naidu, Prasad V. Bharatam","doi":"10.1007/s10142-024-01445-5","DOIUrl":null,"url":null,"abstract":"<div><p>Cancer is a subject of extensive investigation, and the utilization of omics technology has resulted in the generation of substantial volumes of big data in cancer research. Numerous databases are being developed to manage and organize this data effectively. These databases encompass various domains such as genomics, transcriptomics, proteomics, metabolomics, immunology, and drug discovery. The application of computational tools into various core components of pharmaceutical sciences constitutes \"Pharmacoinformatics\", an emerging paradigm in rational drug discovery. The three major features of pharmacoinformatics include (i) Structure modelling of putative drugs and targets, (ii) Compilation of databases and analysis using statistical approaches, and (iii) Employing artificial intelligence/machine learning algorithms for the discovery of novel therapeutic molecules. The development, updating, and analysis of databases using statistical approaches play a pivotal role in pharmacoinformatics. Multiple software tools are associated with oncoinformatics research. This review catalogs the databases and computational tools related to cancer drug discovery and highlights their potential implications in the pharmacoinformatics of cancer.</p><h3>Graphical Abstract</h3><div><figure><div><div><picture><source><img></source></picture></div></div></figure></div></div>","PeriodicalId":574,"journal":{"name":"Functional & Integrative Genomics","volume":"24 5","pages":""},"PeriodicalIF":3.1000,"publicationDate":"2024-09-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Functional & Integrative Genomics","FirstCategoryId":"99","ListUrlMain":"https://link.springer.com/article/10.1007/s10142-024-01445-5","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"GENETICS & HEREDITY","Score":null,"Total":0}
引用次数: 0
Abstract
Cancer is a subject of extensive investigation, and the utilization of omics technology has resulted in the generation of substantial volumes of big data in cancer research. Numerous databases are being developed to manage and organize this data effectively. These databases encompass various domains such as genomics, transcriptomics, proteomics, metabolomics, immunology, and drug discovery. The application of computational tools into various core components of pharmaceutical sciences constitutes "Pharmacoinformatics", an emerging paradigm in rational drug discovery. The three major features of pharmacoinformatics include (i) Structure modelling of putative drugs and targets, (ii) Compilation of databases and analysis using statistical approaches, and (iii) Employing artificial intelligence/machine learning algorithms for the discovery of novel therapeutic molecules. The development, updating, and analysis of databases using statistical approaches play a pivotal role in pharmacoinformatics. Multiple software tools are associated with oncoinformatics research. This review catalogs the databases and computational tools related to cancer drug discovery and highlights their potential implications in the pharmacoinformatics of cancer.
期刊介绍:
Functional & Integrative Genomics is devoted to large-scale studies of genomes and their functions, including systems analyses of biological processes. The journal will provide the research community an integrated platform where researchers can share, review and discuss their findings on important biological questions that will ultimately enable us to answer the fundamental question: How do genomes work?



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
