Huiya Zhang, Yuyu Xing, Yixuan Yang, Bixi Tang, Zhaoyun Zong, Jia Li, Yi Zang, Matthew Bogyo, Xiaojie Lu, Shiyu Chen
{"title":"DNA-Encoded Noncanonical Substrate Library for Protease Profiling","authors":"Huiya Zhang, Yuyu Xing, Yixuan Yang, Bixi Tang, Zhaoyun Zong, Jia Li, Yi Zang, Matthew Bogyo, Xiaojie Lu, Shiyu Chen","doi":"10.1002/cbic.202400559","DOIUrl":null,"url":null,"abstract":"<p>Profiling the substrate sequence preferences of proteases is important for understanding both biological functions as well as for designing protease inhibitors. Several methods are available for profiling the sequence specificity of proteases. However, there is currently no rapid and high-throughput method to profile specificity of proteases for noncanonical substrates. In this study, we described a strategy to use a DNA-encoded noncanonical substrate library to identify the protease substrates composed of both canonical and noncanonical amino acids. This approach uses a DNA-encoded peptide library and introduces a biotin molecule at the N-terminus to immobilize the library on a solid support. Upon protease hydrolysis, the released DNA tag of the substrate peptides can be sequenced to identify the substrate structures. Using this approach, we profiled trypsin and fibroblast activation protein α and discovered noncanonical substrates that were more efficiently cleaved than the commonly used substrates. The identified substrates of FAP were further used to design corresponding covalent inhibitors containing non-canonical sequences with high potency for the target protease. Overall, our approach can aid in the development of new protease substrates and inhibitors.</p>","PeriodicalId":140,"journal":{"name":"ChemBioChem","volume":"25 23","pages":""},"PeriodicalIF":2.8000,"publicationDate":"2024-09-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"ChemBioChem","FirstCategoryId":"99","ListUrlMain":"https://chemistry-europe.onlinelibrary.wiley.com/doi/10.1002/cbic.202400559","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
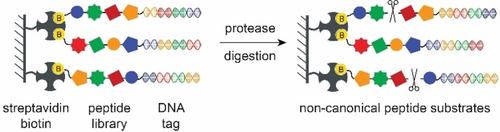
Profiling the substrate sequence preferences of proteases is important for understanding both biological functions as well as for designing protease inhibitors. Several methods are available for profiling the sequence specificity of proteases. However, there is currently no rapid and high-throughput method to profile specificity of proteases for noncanonical substrates. In this study, we described a strategy to use a DNA-encoded noncanonical substrate library to identify the protease substrates composed of both canonical and noncanonical amino acids. This approach uses a DNA-encoded peptide library and introduces a biotin molecule at the N-terminus to immobilize the library on a solid support. Upon protease hydrolysis, the released DNA tag of the substrate peptides can be sequenced to identify the substrate structures. Using this approach, we profiled trypsin and fibroblast activation protein α and discovered noncanonical substrates that were more efficiently cleaved than the commonly used substrates. The identified substrates of FAP were further used to design corresponding covalent inhibitors containing non-canonical sequences with high potency for the target protease. Overall, our approach can aid in the development of new protease substrates and inhibitors.
分析蛋白酶的底物序列偏好对于了解生物功能和设计蛋白酶抑制剂都非常重要。目前有多种方法可用于分析蛋白酶的序列特异性。然而,目前还没有一种快速、高通量的方法来分析蛋白酶对非典型底物的特异性。在这项研究中,我们介绍了一种使用 DNA 编码的非典型底物库来鉴定由典型和非典型氨基酸组成的蛋白酶底物的策略。这种方法使用 DNA 编码的肽库,并在 N 端引入生物素分子,将肽库固定在固体支持物上。蛋白酶水解后,底物肽释放出的 DNA 标记可以通过测序来确定底物结构。利用这种方法,我们对胰蛋白酶和成纤维细胞活化蛋白α进行了分析,发现了比常用底物裂解效率更高的非经典底物。我们还进一步利用确定的 FAP 底物设计了相应的共价抑制剂,这些抑制剂含有对目标蛋白酶具有高效力的非经典序列。总之,我们的方法有助于开发新的蛋白酶底物和抑制剂。
期刊介绍:
ChemBioChem (Impact Factor 2018: 2.641) publishes important breakthroughs across all areas at the interface of chemistry and biology, including the fields of chemical biology, bioorganic chemistry, bioinorganic chemistry, synthetic biology, biocatalysis, bionanotechnology, and biomaterials. It is published on behalf of Chemistry Europe, an association of 16 European chemical societies, and supported by the Asian Chemical Editorial Society (ACES).




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
