Christopher J Warren, Victoria S Edmonds, Nicolette G Payne, Sandeep Voletti, Sarah Y Wu, JennaKay Colquitt, Hossein Sadeghi-Nejad, Nahid Punjani
{"title":"Prompt matters: evaluation of large language model chatbot responses related to Peyronie's disease.","authors":"Christopher J Warren, Victoria S Edmonds, Nicolette G Payne, Sandeep Voletti, Sarah Y Wu, JennaKay Colquitt, Hossein Sadeghi-Nejad, Nahid Punjani","doi":"10.1093/sexmed/qfae055","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Despite direct access to clinicians through the electronic health record, patients are increasingly turning to the internet for information related to their health, especially with sensitive urologic conditions such as Peyronie's disease (PD). Large language model (LLM) chatbots are a form of artificial intelligence that rely on user prompts to mimic conversation, and they have shown remarkable capabilities. The conversational nature of these chatbots has the potential to answer patient questions related to PD; however, the accuracy, comprehensiveness, and readability of these LLMs related to PD remain unknown.</p><p><strong>Aims: </strong>To assess the quality and readability of information generated from 4 LLMs with searches related to PD; to see if users could improve responses; and to assess the accuracy, completeness, and readability of responses to artificial preoperative patient questions sent through the electronic health record prior to undergoing PD surgery.</p><p><strong>Methods: </strong>The National Institutes of Health's frequently asked questions related to PD were entered into 4 LLMs, unprompted and prompted. The responses were evaluated for overall quality by the previously validated DISCERN questionnaire. Accuracy and completeness of LLM responses to 11 presurgical patient messages were evaluated with previously accepted Likert scales. All evaluations were performed by 3 independent reviewers in October 2023, and all reviews were repeated in April 2024. Descriptive statistics and analysis were performed.</p><p><strong>Results: </strong>Without prompting, the quality of information was moderate across all LLMs but improved to high quality with prompting. LLMs were accurate and complete, with an average score of 5.5 of 6.0 (SD, 0.8) and 2.8 of 3.0 (SD, 0.4), respectively. The average Flesch-Kincaid reading level was grade 12.9 (SD, 2.1). Chatbots were unable to communicate at a grade 8 reading level when prompted, and their citations were appropriate only 42.5% of the time.</p><p><strong>Conclusion: </strong>LLMs may become a valuable tool for patient education for PD, but they currently rely on clinical context and appropriate prompting by humans to be useful. Unfortunately, their prerequisite reading level remains higher than that of the average patient, and their citations cannot be trusted. However, given their increasing uptake and accessibility, patients and physicians should be educated on how to interact with these LLMs to elicit the most appropriate responses. In the future, LLMs may reduce burnout by helping physicians respond to patient messages.</p>","PeriodicalId":21782,"journal":{"name":"Sexual Medicine","volume":"12 4","pages":"qfae055"},"PeriodicalIF":2.0000,"publicationDate":"2024-09-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11384107/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Sexual Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1093/sexmed/qfae055","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"MEDICINE, GENERAL & INTERNAL","Score":null,"Total":0}
引用次数: 0
Abstract
Introduction: Despite direct access to clinicians through the electronic health record, patients are increasingly turning to the internet for information related to their health, especially with sensitive urologic conditions such as Peyronie's disease (PD). Large language model (LLM) chatbots are a form of artificial intelligence that rely on user prompts to mimic conversation, and they have shown remarkable capabilities. The conversational nature of these chatbots has the potential to answer patient questions related to PD; however, the accuracy, comprehensiveness, and readability of these LLMs related to PD remain unknown.
Aims: To assess the quality and readability of information generated from 4 LLMs with searches related to PD; to see if users could improve responses; and to assess the accuracy, completeness, and readability of responses to artificial preoperative patient questions sent through the electronic health record prior to undergoing PD surgery.
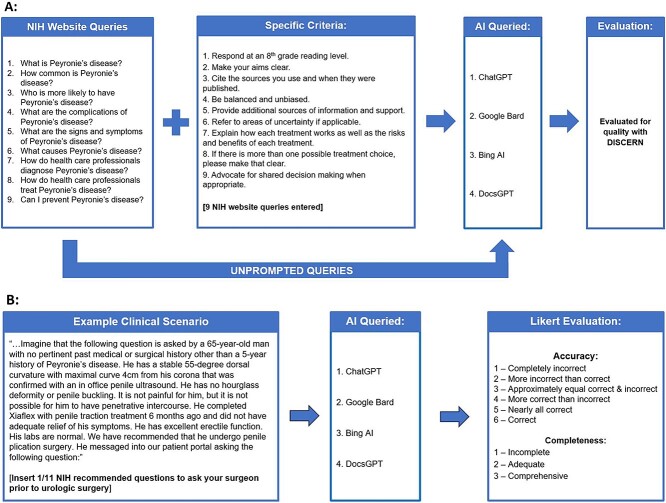
Methods: The National Institutes of Health's frequently asked questions related to PD were entered into 4 LLMs, unprompted and prompted. The responses were evaluated for overall quality by the previously validated DISCERN questionnaire. Accuracy and completeness of LLM responses to 11 presurgical patient messages were evaluated with previously accepted Likert scales. All evaluations were performed by 3 independent reviewers in October 2023, and all reviews were repeated in April 2024. Descriptive statistics and analysis were performed.
Results: Without prompting, the quality of information was moderate across all LLMs but improved to high quality with prompting. LLMs were accurate and complete, with an average score of 5.5 of 6.0 (SD, 0.8) and 2.8 of 3.0 (SD, 0.4), respectively. The average Flesch-Kincaid reading level was grade 12.9 (SD, 2.1). Chatbots were unable to communicate at a grade 8 reading level when prompted, and their citations were appropriate only 42.5% of the time.
Conclusion: LLMs may become a valuable tool for patient education for PD, but they currently rely on clinical context and appropriate prompting by humans to be useful. Unfortunately, their prerequisite reading level remains higher than that of the average patient, and their citations cannot be trusted. However, given their increasing uptake and accessibility, patients and physicians should be educated on how to interact with these LLMs to elicit the most appropriate responses. In the future, LLMs may reduce burnout by helping physicians respond to patient messages.
期刊介绍:
Sexual Medicine is an official publication of the International Society for Sexual Medicine, and serves the field as the peer-reviewed, open access journal for rapid dissemination of multidisciplinary clinical and basic research in all areas of global sexual medicine, and particularly acts as a venue for topics of regional or sub-specialty interest. The journal is focused on issues in clinical medicine and epidemiology but also publishes basic science papers with particular relevance to specific populations. Sexual Medicine offers clinicians and researchers a rapid route to publication and the opportunity to publish in a broadly distributed and highly visible global forum. The journal publishes high quality articles from all over the world and actively seeks submissions from countries with expanding sexual medicine communities. Sexual Medicine relies on the same expert panel of editors and reviewers as The Journal of Sexual Medicine and Sexual Medicine Reviews.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
