Tim Woelfle , Julian Hirt , Perrine Janiaud , Ludwig Kappos , John P.A. Ioannidis , Lars G. Hemkens
{"title":"Benchmarking Human–AI collaboration for common evidence appraisal tools","authors":"Tim Woelfle , Julian Hirt , Perrine Janiaud , Ludwig Kappos , John P.A. Ioannidis , Lars G. Hemkens","doi":"10.1016/j.jclinepi.2024.111533","DOIUrl":null,"url":null,"abstract":"<div><h3>Background and Objective</h3><div>It is unknown whether large language models (LLMs) may facilitate time- and resource-intensive text-related processes in evidence appraisal. The objective was to quantify the agreement of LLMs with human consensus in appraisal of scientific reporting (Preferred Reporting Items for Systematic reviews and Meta-Analyses [PRISMA]) and methodological rigor (A MeaSurement Tool to Assess systematic Reviews [AMSTAR]) of systematic reviews and design of clinical trials (PRagmatic Explanatory Continuum Indicator Summary 2 [PRECIS-2]) and to identify areas where collaboration between humans and artificial intelligence (AI) would outperform the traditional consensus process of human raters in efficiency.</div></div><div><h3>Study Design and Setting</h3><div>Five LLMs (Claude-3-Opus, Claude-2, GPT-4, GPT-3.5, Mixtral-8x22B) assessed 112 systematic reviews applying the PRISMA and AMSTAR criteria and 56 randomized controlled trials applying PRECIS-2. We quantified the agreement between human consensus and (1) individual human raters; (2) individual LLMs; (3) combined LLMs approach; (4) human–AI collaboration. Ratings were marked as deferred (undecided) in case of inconsistency between combined LLMs or between the human rater and the LLM.</div></div><div><h3>Results</h3><div>Individual human rater accuracy was 89% for PRISMA and AMSTAR, and 75% for PRECIS-2. Individual LLM accuracy was ranging from 63% (GPT-3.5) to 70% (Claude-3-Opus) for PRISMA, 53% (GPT-3.5) to 74% (Claude-3-Opus) for AMSTAR, and 38% (GPT-4) to 55% (GPT-3.5) for PRECIS-2. Combined LLM ratings led to accuracies of 75%–88% for PRISMA (4%–74% deferred), 74%–89% for AMSTAR (6%–84% deferred), and 64%–79% for PRECIS-2 (29%–88% deferred). Human–AI collaboration resulted in the best accuracies from 89% to 96% for PRISMA (25/35% deferred), 91%–95% for AMSTAR (27/30% deferred), and 80%–86% for PRECIS-2 (76/71% deferred).</div></div><div><h3>Conclusion</h3><div>Current LLMs alone appraised evidence worse than humans. Human–AI collaboration may reduce workload for the second human rater for the assessment of reporting (PRISMA) and methodological rigor (AMSTAR) but not for complex tasks such as PRECIS-2.</div></div>","PeriodicalId":51079,"journal":{"name":"Journal of Clinical Epidemiology","volume":"175 ","pages":"Article 111533"},"PeriodicalIF":5.2000,"publicationDate":"2024-09-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Clinical Epidemiology","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0895435624002890","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Background and Objective
It is unknown whether large language models (LLMs) may facilitate time- and resource-intensive text-related processes in evidence appraisal. The objective was to quantify the agreement of LLMs with human consensus in appraisal of scientific reporting (Preferred Reporting Items for Systematic reviews and Meta-Analyses [PRISMA]) and methodological rigor (A MeaSurement Tool to Assess systematic Reviews [AMSTAR]) of systematic reviews and design of clinical trials (PRagmatic Explanatory Continuum Indicator Summary 2 [PRECIS-2]) and to identify areas where collaboration between humans and artificial intelligence (AI) would outperform the traditional consensus process of human raters in efficiency.
Study Design and Setting
Five LLMs (Claude-3-Opus, Claude-2, GPT-4, GPT-3.5, Mixtral-8x22B) assessed 112 systematic reviews applying the PRISMA and AMSTAR criteria and 56 randomized controlled trials applying PRECIS-2. We quantified the agreement between human consensus and (1) individual human raters; (2) individual LLMs; (3) combined LLMs approach; (4) human–AI collaboration. Ratings were marked as deferred (undecided) in case of inconsistency between combined LLMs or between the human rater and the LLM.
Results
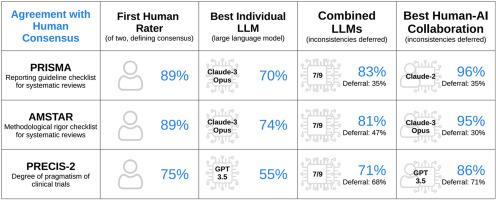
Individual human rater accuracy was 89% for PRISMA and AMSTAR, and 75% for PRECIS-2. Individual LLM accuracy was ranging from 63% (GPT-3.5) to 70% (Claude-3-Opus) for PRISMA, 53% (GPT-3.5) to 74% (Claude-3-Opus) for AMSTAR, and 38% (GPT-4) to 55% (GPT-3.5) for PRECIS-2. Combined LLM ratings led to accuracies of 75%–88% for PRISMA (4%–74% deferred), 74%–89% for AMSTAR (6%–84% deferred), and 64%–79% for PRECIS-2 (29%–88% deferred). Human–AI collaboration resulted in the best accuracies from 89% to 96% for PRISMA (25/35% deferred), 91%–95% for AMSTAR (27/30% deferred), and 80%–86% for PRECIS-2 (76/71% deferred).
Conclusion
Current LLMs alone appraised evidence worse than humans. Human–AI collaboration may reduce workload for the second human rater for the assessment of reporting (PRISMA) and methodological rigor (AMSTAR) but not for complex tasks such as PRECIS-2.
期刊介绍:
The Journal of Clinical Epidemiology strives to enhance the quality of clinical and patient-oriented healthcare research by advancing and applying innovative methods in conducting, presenting, synthesizing, disseminating, and translating research results into optimal clinical practice. Special emphasis is placed on training new generations of scientists and clinical practice leaders.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
