Veronica Mandelli, Ines Severino, Lisa Eyler, Karen Pierce, Eric Courchesne, Michael V Lombardo
{"title":"A 3D approach to understanding heterogeneity in early developing autisms.","authors":"Veronica Mandelli, Ines Severino, Lisa Eyler, Karen Pierce, Eric Courchesne, Michael V Lombardo","doi":"10.1186/s13229-024-00613-5","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Phenotypic heterogeneity in early language, intellectual, motor, and adaptive functioning (LIMA) features are amongst the most striking features that distinguish different types of autistic individuals. Yet the current diagnostic criteria uses a single label of autism and implicitly emphasizes what individuals have in common as core social-communicative and restricted repetitive behavior difficulties. Subtype labels based on the non-core LIMA features may help to more meaningfully distinguish types of autisms with differing developmental paths and differential underlying biology.</p><p><strong>Methods: </strong>Unsupervised data-driven subtypes were identified using stability-based relative clustering validation on publicly available Mullen Scales of Early Learning (MSEL) and Vineland Adaptive Behavior Scales (VABS) data (n = 615; age = 24-68 months) from the National Institute of Mental Health Data Archive (NDA). Differential developmental trajectories between subtypes were tested on longitudinal data from NDA and from an independent in-house dataset from UCSD. A subset of the UCSD dataset was also tested for subtype differences in functional and structural neuroimaging phenotypes and relationships with blood gene expression. The current subtyping model was also compared to early language outcome subtypes derived from past work.</p><p><strong>Results: </strong>Two autism subtypes can be identified based on early phenotypic LIMA features. These data-driven subtypes are robust in the population and can be identified in independent data with 98% accuracy. The subtypes can be described as Type I versus Type II autisms differentiated by relatively high versus low scores on LIMA features. These two types of autisms are also distinguished by different developmental trajectories over the first decade of life. Finally, these two types of autisms reveal striking differences in functional and structural neuroimaging phenotypes and their relationships with gene expression and may highlight unique biological mechanisms.</p><p><strong>Limitations: </strong>Sample sizes for the neuroimaging and gene expression dataset are relatively small and require further independent replication. The current work is also limited to subtyping based on MSEL and VABS phenotypic measures.</p><p><strong>Conclusions: </strong>This work emphasizes the potential importance of stratifying autism by a Type I versus Type II distinction focused on LIMA features and which may be of high prognostic and biological significance.</p>","PeriodicalId":18733,"journal":{"name":"Molecular Autism","volume":"15 1","pages":"41"},"PeriodicalIF":5.5000,"publicationDate":"2024-09-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11443946/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Molecular Autism","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s13229-024-00613-5","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"GENETICS & HEREDITY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Phenotypic heterogeneity in early language, intellectual, motor, and adaptive functioning (LIMA) features are amongst the most striking features that distinguish different types of autistic individuals. Yet the current diagnostic criteria uses a single label of autism and implicitly emphasizes what individuals have in common as core social-communicative and restricted repetitive behavior difficulties. Subtype labels based on the non-core LIMA features may help to more meaningfully distinguish types of autisms with differing developmental paths and differential underlying biology.
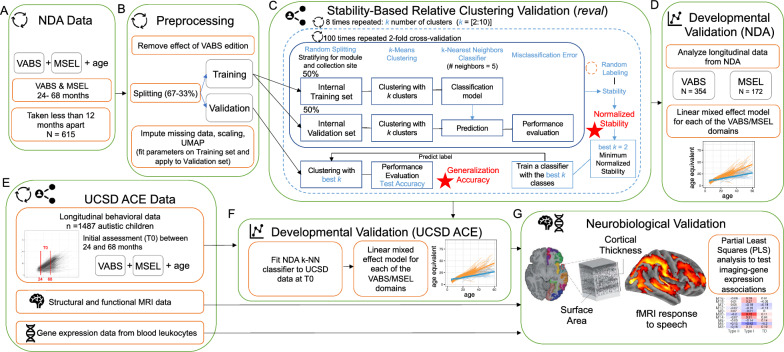
Methods: Unsupervised data-driven subtypes were identified using stability-based relative clustering validation on publicly available Mullen Scales of Early Learning (MSEL) and Vineland Adaptive Behavior Scales (VABS) data (n = 615; age = 24-68 months) from the National Institute of Mental Health Data Archive (NDA). Differential developmental trajectories between subtypes were tested on longitudinal data from NDA and from an independent in-house dataset from UCSD. A subset of the UCSD dataset was also tested for subtype differences in functional and structural neuroimaging phenotypes and relationships with blood gene expression. The current subtyping model was also compared to early language outcome subtypes derived from past work.
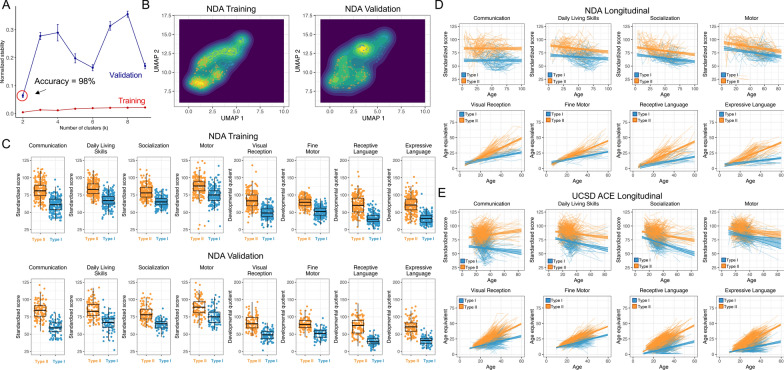
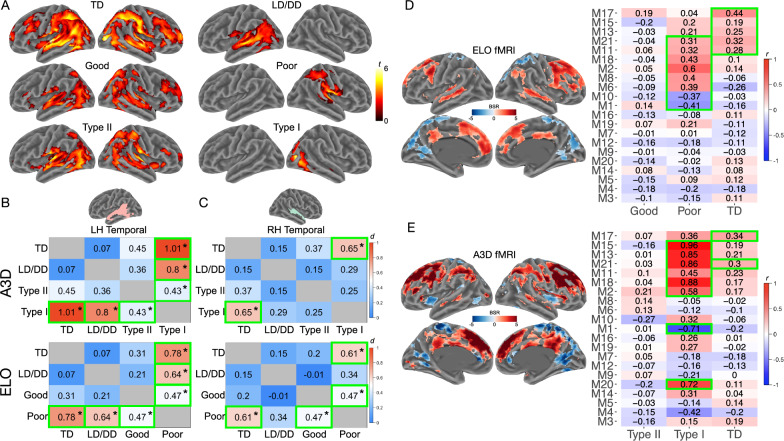
Results: Two autism subtypes can be identified based on early phenotypic LIMA features. These data-driven subtypes are robust in the population and can be identified in independent data with 98% accuracy. The subtypes can be described as Type I versus Type II autisms differentiated by relatively high versus low scores on LIMA features. These two types of autisms are also distinguished by different developmental trajectories over the first decade of life. Finally, these two types of autisms reveal striking differences in functional and structural neuroimaging phenotypes and their relationships with gene expression and may highlight unique biological mechanisms.
Limitations: Sample sizes for the neuroimaging and gene expression dataset are relatively small and require further independent replication. The current work is also limited to subtyping based on MSEL and VABS phenotypic measures.
Conclusions: This work emphasizes the potential importance of stratifying autism by a Type I versus Type II distinction focused on LIMA features and which may be of high prognostic and biological significance.
背景:早期语言、智力、运动和适应功能(LIMA)特征的表型异质性是区分不同类型自闭症患者的最显著特征之一。然而,目前的诊断标准使用单一的自闭症标签,并隐含地强调个体的共同点,即核心的社交-沟通和限制性重复行为障碍。基于 LIMA 非核心特征的亚型标签可能有助于更有意义地区分具有不同发展路径和不同潜在生物学特征的自闭症类型:方法:采用基于稳定性的相对聚类验证,对美国国家心理健康研究所数据档案(NDA)中公开提供的穆伦早期学习量表(MSEL)和文兰适应行为量表(VABS)数据(n = 615;年龄 = 24-68 个月)进行无监督数据驱动的亚型鉴定。亚型之间的差异发展轨迹通过 NDA 的纵向数据和加州大学圣地亚哥分校的独立内部数据集进行了测试。此外,还对加州大学旧金山分校数据集的一个子集进行了测试,以了解亚型在功能和结构神经影像表型方面的差异以及与血液基因表达的关系。目前的亚型模型还与过去工作中得出的早期语言结果亚型进行了比较:结果:根据 LIMA 的早期表型特征,可以确定两种自闭症亚型。这些数据驱动的亚型在人群中是稳健的,并能在独立数据中以 98% 的准确率识别出来。这些亚型可被描述为 I 型和 II 型自闭症,根据 LIMA 特征的相对高分和低分加以区分。这两类自闭症在出生后前十年的发展轨迹也有所不同。最后,这两种类型的自闭症在功能和结构神经影像表型及其与基因表达的关系方面存在显著差异,并可能突显出独特的生物学机制:局限性:神经影像和基因表达数据集的样本量相对较小,需要进一步独立复制。目前的工作还仅限于基于 MSEL 和 VABS 表型测量的亚型划分:这项工作强调了根据 LIMA 特征对自闭症进行 I 型和 II 型分层的潜在重要性,这可能具有很高的预后和生物学意义。
期刊介绍:
Molecular Autism is a peer-reviewed, open access journal that publishes high-quality basic, translational and clinical research that has relevance to the etiology, pathobiology, or treatment of autism and related neurodevelopmental conditions. Research that includes integration across levels is encouraged. Molecular Autism publishes empirical studies, reviews, and brief communications.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
