Syed Rakin Ahmed, Didem Egemen, Brian Befano, Ana Cecilia Rodriguez, Jose Jeronimo, Kanan Desai, Carolina Teran, Karla Alfaro, Joel Fokom-Domgue, Kittipat Charoenkwan, Chemtai Mungo, Rebecca Luckett, Rakiya Saidu, Taina Raiol, Ana Ribeiro, Julia C Gage, Silvia de Sanjose, Jayashree Kalpathy-Cramer, Mark Schiffman
{"title":"Assessing generalizability of an AI-based visual test for cervical cancer screening.","authors":"Syed Rakin Ahmed, Didem Egemen, Brian Befano, Ana Cecilia Rodriguez, Jose Jeronimo, Kanan Desai, Carolina Teran, Karla Alfaro, Joel Fokom-Domgue, Kittipat Charoenkwan, Chemtai Mungo, Rebecca Luckett, Rakiya Saidu, Taina Raiol, Ana Ribeiro, Julia C Gage, Silvia de Sanjose, Jayashree Kalpathy-Cramer, Mark Schiffman","doi":"10.1371/journal.pdig.0000364","DOIUrl":null,"url":null,"abstract":"<p><p>A number of challenges hinder artificial intelligence (AI) models from effective clinical translation. Foremost among these challenges is the lack of generalizability, which is defined as the ability of a model to perform well on datasets that have different characteristics from the training data. We recently investigated the development of an AI pipeline on digital images of the cervix, utilizing a multi-heterogeneous dataset of 9,462 women (17,013 images) and a multi-stage model selection and optimization approach, to generate a diagnostic classifier able to classify images of the cervix into \"normal\", \"indeterminate\" and \"precancer/cancer\" (denoted as \"precancer+\") categories. In this work, we investigate the performance of this multiclass classifier on external data not utilized in training and internal validation, to assess the generalizability of the classifier when moving to new settings. We assessed both the classification performance and repeatability of our classifier model across the two axes of heterogeneity present in our dataset: image capture device and geography, utilizing both out-of-the-box inference and retraining with external data. Our results demonstrate that device-level heterogeneity affects our model performance more than geography-level heterogeneity. Classification performance of our model is strong on images from a new geography without retraining, while incremental retraining with inclusion of images from a new device progressively improves classification performance on that device up to a point of saturation. Repeatability of our model is relatively unaffected by data heterogeneity and remains strong throughout. Our work supports the need for optimized retraining approaches that address data heterogeneity (e.g., when moving to a new device) to facilitate effective use of AI models in new settings.</p>","PeriodicalId":74465,"journal":{"name":"PLOS digital health","volume":"3 10","pages":"e0000364"},"PeriodicalIF":7.7000,"publicationDate":"2024-10-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11446437/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLOS digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1371/journal.pdig.0000364","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
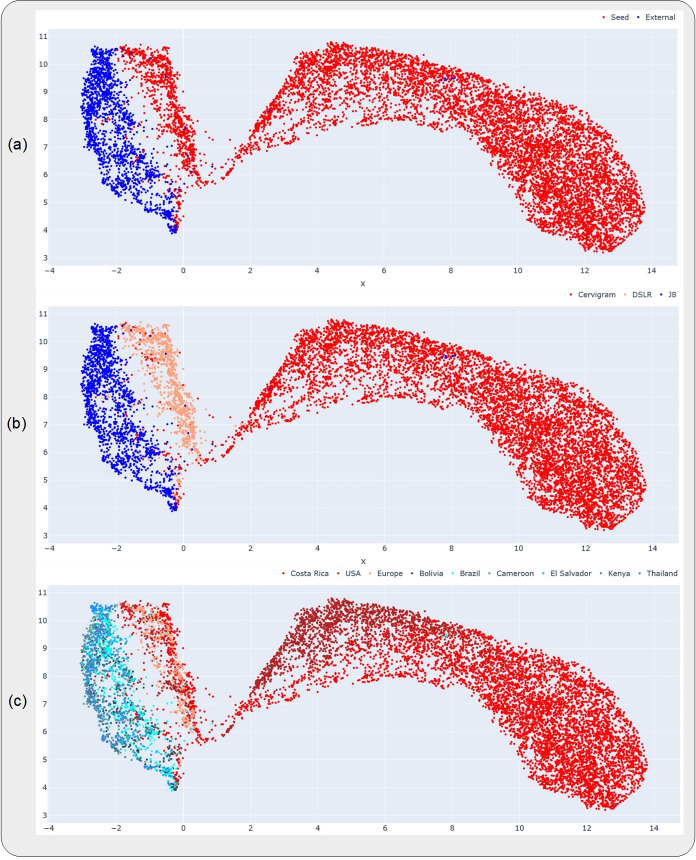
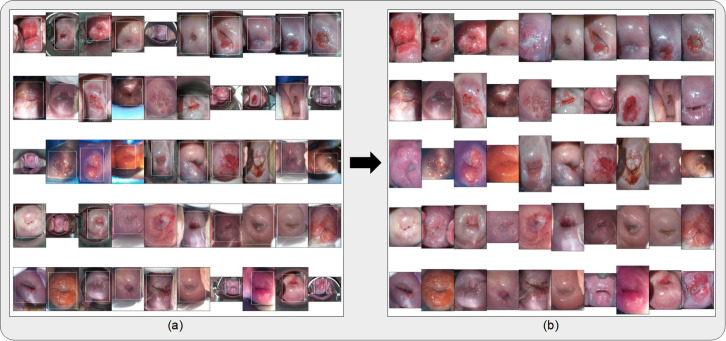
A number of challenges hinder artificial intelligence (AI) models from effective clinical translation. Foremost among these challenges is the lack of generalizability, which is defined as the ability of a model to perform well on datasets that have different characteristics from the training data. We recently investigated the development of an AI pipeline on digital images of the cervix, utilizing a multi-heterogeneous dataset of 9,462 women (17,013 images) and a multi-stage model selection and optimization approach, to generate a diagnostic classifier able to classify images of the cervix into "normal", "indeterminate" and "precancer/cancer" (denoted as "precancer+") categories. In this work, we investigate the performance of this multiclass classifier on external data not utilized in training and internal validation, to assess the generalizability of the classifier when moving to new settings. We assessed both the classification performance and repeatability of our classifier model across the two axes of heterogeneity present in our dataset: image capture device and geography, utilizing both out-of-the-box inference and retraining with external data. Our results demonstrate that device-level heterogeneity affects our model performance more than geography-level heterogeneity. Classification performance of our model is strong on images from a new geography without retraining, while incremental retraining with inclusion of images from a new device progressively improves classification performance on that device up to a point of saturation. Repeatability of our model is relatively unaffected by data heterogeneity and remains strong throughout. Our work supports the need for optimized retraining approaches that address data heterogeneity (e.g., when moving to a new device) to facilitate effective use of AI models in new settings.
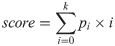


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
