Unpacking unstructured data: A pilot study on extracting insights from neuropathological reports of Parkinson's Disease patients using large language models.
Oleg Stroganov, Amber Schedlbauer, Emily Lorenzen, Alex Kadhim, Anna Lobanova, David A Lewis, Jill R Glausier
{"title":"Unpacking unstructured data: A pilot study on extracting insights from neuropathological reports of Parkinson's Disease patients using large language models.","authors":"Oleg Stroganov, Amber Schedlbauer, Emily Lorenzen, Alex Kadhim, Anna Lobanova, David A Lewis, Jill R Glausier","doi":"10.1093/biomethods/bpae072","DOIUrl":null,"url":null,"abstract":"<p><p>The aim of this study was to make unstructured neuropathological data, located in the NeuroBioBank (NBB), follow Findability, Accessibility, Interoperability, and Reusability principles and investigate the potential of large language models (LLMs) in wrangling unstructured neuropathological reports. By making the currently inconsistent and disparate data findable, our overarching goal was to enhance research output and speed. The NBB catalog currently includes information from medical records, interview results, and neuropathological reports. These reports contain crucial information necessary for conducting an in-depth analysis of NBB data but have multiple formats that vary across different NBB biorepositories and change over time. In this study, we focused on a subset of 822 donors with Parkinson's disease (PD) from seven NBB biorepositories. We developed a data model with combined Brain Region and Pathological Findings data at its core. This approach made it easier to build an extraction pipeline and was flexible enough to convert resulting data to Common Data Elements, a standardized data collection tool used by the neuroscience community to improve consistency and facilitate data sharing across studies. This pilot study demonstrated the potential of LLMs in structuring unstructured neuropathological reports of PD patients available in the NBB. The pipeline enabled successful extraction of detailed tissue-level (microscopic) and gross anatomical (macroscopic) observations, along with staging information from pathology reports, with extraction quality comparable to manual curation results. To our knowledge, this is the first attempt to automatically standardize neuropathological information at this scale. The collected data have the potential to serve as a valuable resource for PD researchers, facilitating integration with clinical information and genetic data (such as genome-wide genotyping and whole-genome sequencing) available through the NBB, thereby enabling a more comprehensive understanding of the disease.</p>","PeriodicalId":36528,"journal":{"name":"Biology Methods and Protocols","volume":"9 1","pages":"bpae072"},"PeriodicalIF":1.3000,"publicationDate":"2024-10-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11513015/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biology Methods and Protocols","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/biomethods/bpae072","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
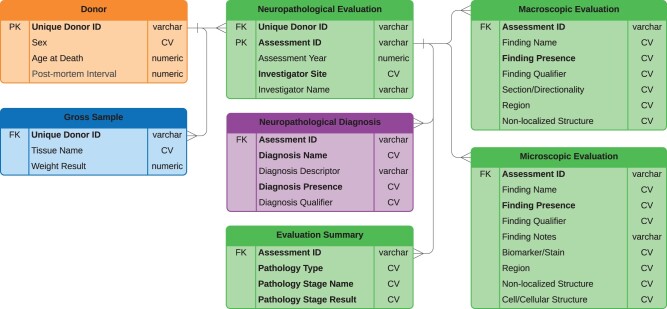
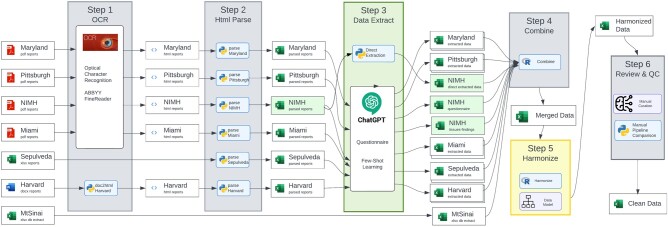
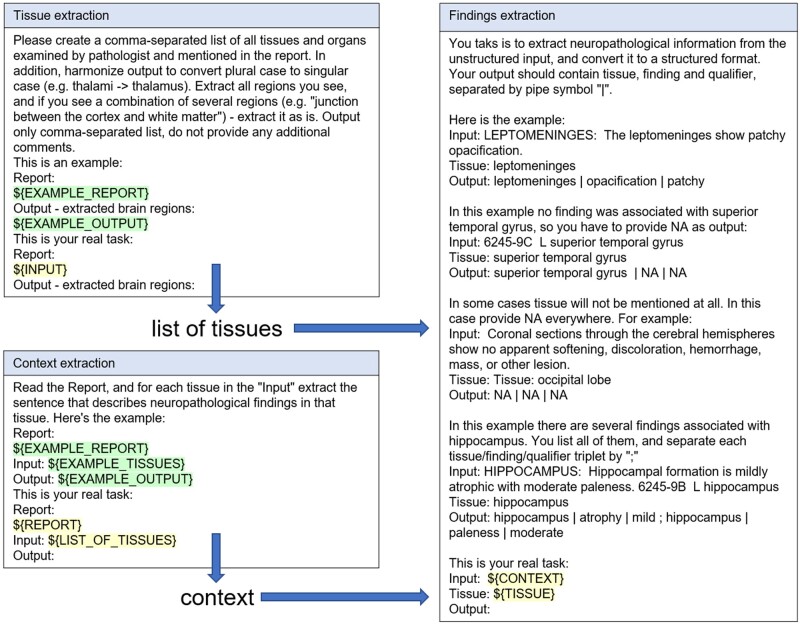
The aim of this study was to make unstructured neuropathological data, located in the NeuroBioBank (NBB), follow Findability, Accessibility, Interoperability, and Reusability principles and investigate the potential of large language models (LLMs) in wrangling unstructured neuropathological reports. By making the currently inconsistent and disparate data findable, our overarching goal was to enhance research output and speed. The NBB catalog currently includes information from medical records, interview results, and neuropathological reports. These reports contain crucial information necessary for conducting an in-depth analysis of NBB data but have multiple formats that vary across different NBB biorepositories and change over time. In this study, we focused on a subset of 822 donors with Parkinson's disease (PD) from seven NBB biorepositories. We developed a data model with combined Brain Region and Pathological Findings data at its core. This approach made it easier to build an extraction pipeline and was flexible enough to convert resulting data to Common Data Elements, a standardized data collection tool used by the neuroscience community to improve consistency and facilitate data sharing across studies. This pilot study demonstrated the potential of LLMs in structuring unstructured neuropathological reports of PD patients available in the NBB. The pipeline enabled successful extraction of detailed tissue-level (microscopic) and gross anatomical (macroscopic) observations, along with staging information from pathology reports, with extraction quality comparable to manual curation results. To our knowledge, this is the first attempt to automatically standardize neuropathological information at this scale. The collected data have the potential to serve as a valuable resource for PD researchers, facilitating integration with clinical information and genetic data (such as genome-wide genotyping and whole-genome sequencing) available through the NBB, thereby enabling a more comprehensive understanding of the disease.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
