Marta Fernandes, M Brandon Westover, Aneesh B Singhal, Sahar F Zafar
{"title":"Automated Extraction of Stroke Severity From Unstructured Electronic Health Records Using Natural Language Processing.","authors":"Marta Fernandes, M Brandon Westover, Aneesh B Singhal, Sahar F Zafar","doi":"10.1161/JAHA.124.036386","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Multicenter electronic health records can support quality improvement and comparative effectiveness research in stroke. However, limitations of electronic health record-based research include challenges in abstracting key clinical variables, including stroke severity, along with missing data. We developed a natural language processing model that reads electronic health record notes to directly extract the National Institutes of Health Stroke Scale score when documented and predict the score from clinical documentation when missing.</p><p><strong>Methods and results: </strong>The study included notes from patients with acute stroke (aged ≥18 years) admitted to Massachusetts General Hospital (2015-2022). The Massachusetts General Hospital data were divided into training/holdout test (70%/30%) sets. We developed a 2-stage model to predict the admission National Institutes of Health Stroke Scale, obtained from the GWTG (Get With The Guidelines) stroke registry. We trained a model with the least absolute shrinkage and selection operator. For test notes with documented National Institutes of Health Stroke Scale, scores were extracted using regular expressions (stage 1); when not documented, least absolute shrinkage and selection operator was used for prediction (stage 2). The 2-stage model was tested on the holdout test set and validated in the Medical Information Mart for Intensive Care (2001-2012) version 1.4, using root mean squared error and Spearman correlation. We included 4163 patients (Massachusetts General Hospital, 3876; Medical Information Mart for Intensive Care, 287); average age, 69 (SD, 15) years; 53% men, and 72% White individuals. The model achieved a root mean squared error of 2.89 (95% CI, 2.62-3.19) and Spearman correlation of 0.92 (95% CI, 0.91-0.93) in the Massachusetts General Hospital test set, and 2.20 (95% CI, 1.69-2.66) and 0.96 (95% CI, 0.94-0.97) in the MIMIC validation set, respectively.</p><p><strong>Conclusions: </strong>The automatic natural language processing-based model can enable large-scale stroke severity phenotyping from the electronic health record and support real-world quality improvement and comparative effectiveness studies in stroke.</p>","PeriodicalId":54370,"journal":{"name":"Journal of the American Heart Association","volume":" ","pages":"e036386"},"PeriodicalIF":5.3000,"publicationDate":"2024-11-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11935650/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of the American Heart Association","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1161/JAHA.124.036386","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/25 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"CARDIAC & CARDIOVASCULAR SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Multicenter electronic health records can support quality improvement and comparative effectiveness research in stroke. However, limitations of electronic health record-based research include challenges in abstracting key clinical variables, including stroke severity, along with missing data. We developed a natural language processing model that reads electronic health record notes to directly extract the National Institutes of Health Stroke Scale score when documented and predict the score from clinical documentation when missing.
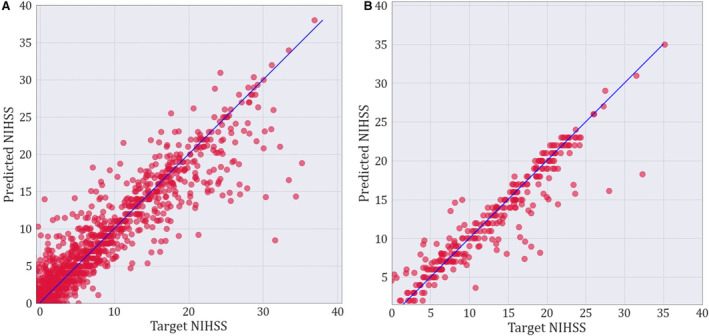
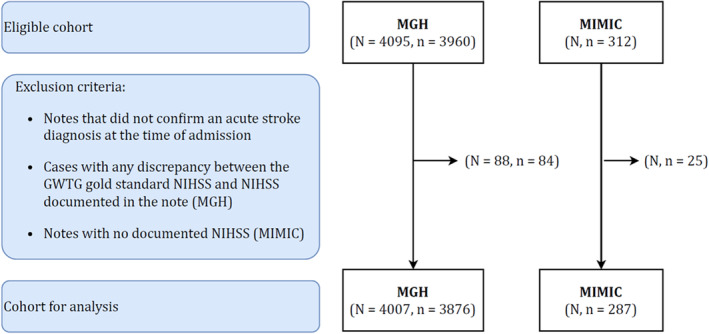
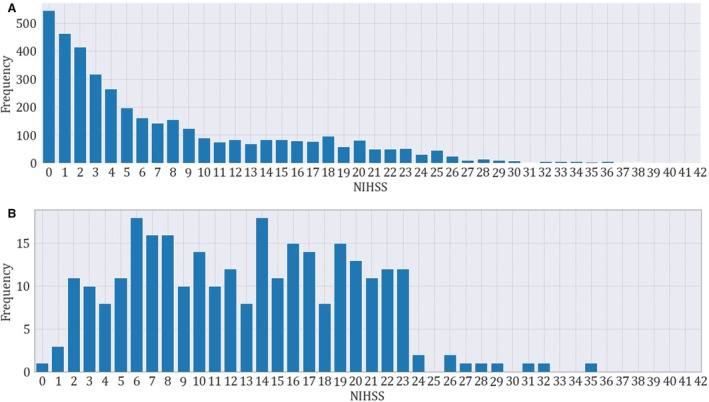
Methods and results: The study included notes from patients with acute stroke (aged ≥18 years) admitted to Massachusetts General Hospital (2015-2022). The Massachusetts General Hospital data were divided into training/holdout test (70%/30%) sets. We developed a 2-stage model to predict the admission National Institutes of Health Stroke Scale, obtained from the GWTG (Get With The Guidelines) stroke registry. We trained a model with the least absolute shrinkage and selection operator. For test notes with documented National Institutes of Health Stroke Scale, scores were extracted using regular expressions (stage 1); when not documented, least absolute shrinkage and selection operator was used for prediction (stage 2). The 2-stage model was tested on the holdout test set and validated in the Medical Information Mart for Intensive Care (2001-2012) version 1.4, using root mean squared error and Spearman correlation. We included 4163 patients (Massachusetts General Hospital, 3876; Medical Information Mart for Intensive Care, 287); average age, 69 (SD, 15) years; 53% men, and 72% White individuals. The model achieved a root mean squared error of 2.89 (95% CI, 2.62-3.19) and Spearman correlation of 0.92 (95% CI, 0.91-0.93) in the Massachusetts General Hospital test set, and 2.20 (95% CI, 1.69-2.66) and 0.96 (95% CI, 0.94-0.97) in the MIMIC validation set, respectively.
Conclusions: The automatic natural language processing-based model can enable large-scale stroke severity phenotyping from the electronic health record and support real-world quality improvement and comparative effectiveness studies in stroke.
期刊介绍:
As an Open Access journal, JAHA - Journal of the American Heart Association is rapidly and freely available, accelerating the translation of strong science into effective practice.
JAHA is an authoritative, peer-reviewed Open Access journal focusing on cardiovascular and cerebrovascular disease. JAHA provides a global forum for basic and clinical research and timely reviews on cardiovascular disease and stroke. As an Open Access journal, its content is free on publication to read, download, and share, accelerating the translation of strong science into effective practice.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
