Henning Schäfer , Ahmad Idrissi-Yaghir , Kamyar Arzideh , Hendrik Damm , Tabea M.G. Pakull , Cynthia S. Schmidt , Mikel Bahn , Georg Lodde , Elisabeth Livingstone , Dirk Schadendorf , Felix Nensa , Peter A. Horn , Christoph M. Friedrich
{"title":"BioKGrapher: Initial evaluation of automated knowledge graph construction from biomedical literature","authors":"Henning Schäfer , Ahmad Idrissi-Yaghir , Kamyar Arzideh , Hendrik Damm , Tabea M.G. Pakull , Cynthia S. Schmidt , Mikel Bahn , Georg Lodde , Elisabeth Livingstone , Dirk Schadendorf , Felix Nensa , Peter A. Horn , Christoph M. Friedrich","doi":"10.1016/j.csbj.2024.10.017","DOIUrl":null,"url":null,"abstract":"<div><div><strong>Background</strong> The growth of biomedical literature presents challenges in extracting and structuring knowledge. Knowledge Graphs (KGs) offer a solution by representing relationships between biomedical entities. However, manual construction of KGs is labor-intensive and time-consuming, highlighting the need for automated methods. This work introduces BioKGrapher, a tool for automatic KG construction using large-scale publication data, with a focus on biomedical concepts related to specific medical conditions. BioKGrapher allows researchers to construct KGs from PubMed IDs.</div><div><strong>Methods</strong> The BioKGrapher pipeline begins with Named Entity Recognition and Linking (NER+NEL) to extract and normalize biomedical concepts from PubMed, mapping them to the Unified Medical Language System (UMLS). Extracted concepts are weighted and re-ranked using Kullback-Leibler divergence and local frequency balancing. These concepts are then integrated into hierarchical KGs, with relationships formed using terminologies like SNOMED CT and NCIt. Downstream applications include multi-label document classification using Adapter-infused Transformer models.</div><div><strong>Results</strong> BioKGrapher effectively aligns generated concepts with clinical practice guidelines from the German Guideline Program in Oncology (GGPO), achieving <span><math><msub><mrow><mi>F</mi></mrow><mrow><mn>1</mn></mrow></msub></math></span>-Scores of up to 0.6. In multi-label classification, Adapter-infused models using a BioKGrapher cancer-specific KG improved micro <span><math><msub><mrow><mi>F</mi></mrow><mrow><mn>1</mn></mrow></msub></math></span>-Scores by up to 0.89 percentage points over a non-specific KG and 2.16 points over base models across three BERT variants. The drug-disease extraction case study identified indications for Nivolumab and Rituximab.</div><div><strong>Conclusion</strong> BioKGrapher is a tool for automatic KG construction, aligning with the GGPO and enhancing downstream task performance. It offers a scalable solution for managing biomedical knowledge, with potential applications in literature recommendation, decision support, and drug repurposing.</div></div>","PeriodicalId":10715,"journal":{"name":"Computational and structural biotechnology journal","volume":"24 ","pages":"Pages 639-660"},"PeriodicalIF":4.1000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational and structural biotechnology journal","FirstCategoryId":"99","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2001037024003386","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/17 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
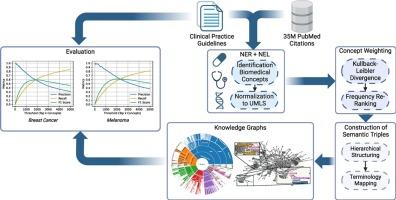
Background The growth of biomedical literature presents challenges in extracting and structuring knowledge. Knowledge Graphs (KGs) offer a solution by representing relationships between biomedical entities. However, manual construction of KGs is labor-intensive and time-consuming, highlighting the need for automated methods. This work introduces BioKGrapher, a tool for automatic KG construction using large-scale publication data, with a focus on biomedical concepts related to specific medical conditions. BioKGrapher allows researchers to construct KGs from PubMed IDs.
Methods The BioKGrapher pipeline begins with Named Entity Recognition and Linking (NER+NEL) to extract and normalize biomedical concepts from PubMed, mapping them to the Unified Medical Language System (UMLS). Extracted concepts are weighted and re-ranked using Kullback-Leibler divergence and local frequency balancing. These concepts are then integrated into hierarchical KGs, with relationships formed using terminologies like SNOMED CT and NCIt. Downstream applications include multi-label document classification using Adapter-infused Transformer models.
Results BioKGrapher effectively aligns generated concepts with clinical practice guidelines from the German Guideline Program in Oncology (GGPO), achieving -Scores of up to 0.6. In multi-label classification, Adapter-infused models using a BioKGrapher cancer-specific KG improved micro -Scores by up to 0.89 percentage points over a non-specific KG and 2.16 points over base models across three BERT variants. The drug-disease extraction case study identified indications for Nivolumab and Rituximab.
Conclusion BioKGrapher is a tool for automatic KG construction, aligning with the GGPO and enhancing downstream task performance. It offers a scalable solution for managing biomedical knowledge, with potential applications in literature recommendation, decision support, and drug repurposing.
期刊介绍:
Computational and Structural Biotechnology Journal (CSBJ) is an online gold open access journal publishing research articles and reviews after full peer review. All articles are published, without barriers to access, immediately upon acceptance. The journal places a strong emphasis on functional and mechanistic understanding of how molecular components in a biological process work together through the application of computational methods. Structural data may provide such insights, but they are not a pre-requisite for publication in the journal. Specific areas of interest include, but are not limited to:
Structure and function of proteins, nucleic acids and other macromolecules
Structure and function of multi-component complexes
Protein folding, processing and degradation
Enzymology
Computational and structural studies of plant systems
Microbial Informatics
Genomics
Proteomics
Metabolomics
Algorithms and Hypothesis in Bioinformatics
Mathematical and Theoretical Biology
Computational Chemistry and Drug Discovery
Microscopy and Molecular Imaging
Nanotechnology
Systems and Synthetic Biology



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
