Nianchang Huang , Yang Yang , Qiang Zhang , Jungong Han , Jin Huang
{"title":"Lightweight cross-modal transformer for RGB-D salient object detection","authors":"Nianchang Huang , Yang Yang , Qiang Zhang , Jungong Han , Jin Huang","doi":"10.1016/j.cviu.2024.104194","DOIUrl":null,"url":null,"abstract":"<div><div>Recently, Transformer-based RGB-D salient object detection (SOD) models have pushed the performance to a new level. However, they come at the cost of consuming abundant resources, including memory and power, thus hindering their real-life applications. To remedy this situation, a novel lightweight cross-modal Transformer (LCT) for RGB-D SOD will be presented in this paper. Specifically, LCT will first reduce its parameters and computational costs by employing a middle-level feature fusion structure and taking a lightweight Transformer as the backbone. Then, with the aid of Transformers, it will compensate for performance degradation by effectively capturing the cross-modal and cross-level complementary information from the multi-modal input images. To this end, a cross-modal enhancement and fusion module (CEFM) with a lightweight channel-wise cross attention block (LCCAB) will be designed to capture the cross-modal complementary information effectively but with fewer costs. A bi-directional multi-level feature interaction module (Bi-MFIM) with a lightweight spatial-wise cross attention block (LSCAB) will be designed to capture the cross-level complementary context information. By virtue of CEFM and Bi-MFIM, the performance degradation caused by parameter reduction can be well compensated, thus boosting the performances. By doing so, our proposed model has only 2.8M parameters with 7.6G FLOPs and runs at 66 FPS. Furthermore, experimental results on several benchmark datasets show that our proposed model can achieve competitive or even better results than other models. Our code will be released on <span><span>https://github.com/nexiakele/lightweight-cross-modal-Transformer-LCT-for-RGB-D-SOD</span><svg><path></path></svg></span>.</div></div>","PeriodicalId":50633,"journal":{"name":"Computer Vision and Image Understanding","volume":"249 ","pages":"Article 104194"},"PeriodicalIF":3.5000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Vision and Image Understanding","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1077314224002753","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/17 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
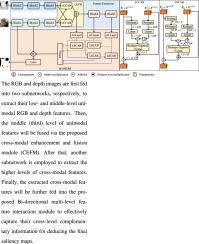
Recently, Transformer-based RGB-D salient object detection (SOD) models have pushed the performance to a new level. However, they come at the cost of consuming abundant resources, including memory and power, thus hindering their real-life applications. To remedy this situation, a novel lightweight cross-modal Transformer (LCT) for RGB-D SOD will be presented in this paper. Specifically, LCT will first reduce its parameters and computational costs by employing a middle-level feature fusion structure and taking a lightweight Transformer as the backbone. Then, with the aid of Transformers, it will compensate for performance degradation by effectively capturing the cross-modal and cross-level complementary information from the multi-modal input images. To this end, a cross-modal enhancement and fusion module (CEFM) with a lightweight channel-wise cross attention block (LCCAB) will be designed to capture the cross-modal complementary information effectively but with fewer costs. A bi-directional multi-level feature interaction module (Bi-MFIM) with a lightweight spatial-wise cross attention block (LSCAB) will be designed to capture the cross-level complementary context information. By virtue of CEFM and Bi-MFIM, the performance degradation caused by parameter reduction can be well compensated, thus boosting the performances. By doing so, our proposed model has only 2.8M parameters with 7.6G FLOPs and runs at 66 FPS. Furthermore, experimental results on several benchmark datasets show that our proposed model can achieve competitive or even better results than other models. Our code will be released on https://github.com/nexiakele/lightweight-cross-modal-Transformer-LCT-for-RGB-D-SOD.
期刊介绍:
The central focus of this journal is the computer analysis of pictorial information. Computer Vision and Image Understanding publishes papers covering all aspects of image analysis from the low-level, iconic processes of early vision to the high-level, symbolic processes of recognition and interpretation. A wide range of topics in the image understanding area is covered, including papers offering insights that differ from predominant views.
Research Areas Include:
• Theory
• Early vision
• Data structures and representations
• Shape
• Range
• Motion
• Matching and recognition
• Architecture and languages
• Vision systems



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
