Assessing the Role of the Generative Pretrained Transformer (GPT) in Alzheimer's Disease Management: Comparative Study of Neurologist- and Artificial Intelligence-Generated Responses.
Jiaqi Zeng, Xiaoyi Zou, Shirong Li, Yao Tang, Sisi Teng, Huanhuan Li, Changyu Wang, Yuxuan Wu, Luyao Zhang, Yunheng Zhong, Jialin Liu, Siru Liu
{"title":"Assessing the Role of the Generative Pretrained Transformer (GPT) in Alzheimer's Disease Management: Comparative Study of Neurologist- and Artificial Intelligence-Generated Responses.","authors":"Jiaqi Zeng, Xiaoyi Zou, Shirong Li, Yao Tang, Sisi Teng, Huanhuan Li, Changyu Wang, Yuxuan Wu, Luyao Zhang, Yunheng Zhong, Jialin Liu, Siru Liu","doi":"10.2196/51095","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Alzheimer's disease (AD) is a progressive neurodegenerative disorder posing challenges to patients, caregivers, and society. Accessible and accurate information is crucial for effective AD management.</p><p><strong>Objective: </strong>This study aimed to evaluate the accuracy, comprehensibility, clarity, and usefulness of the Generative Pretrained Transformer's (GPT) answers concerning the management and caregiving of patients with AD.</p><p><strong>Methods: </strong>In total, 14 questions related to the prevention, treatment, and care of AD were identified and posed to GPT-3.5 and GPT-4 in Chinese and English, respectively, and 4 respondent neurologists were asked to answer them. We generated 8 sets of responses (total 112) and randomly coded them in answer sheets. Next, 5 evaluator neurologists and 5 family members of patients were asked to rate the 112 responses using separate 5-point Likert scales. We evaluated the quality of the responses using a set of 8 questions rated on a 5-point Likert scale. To gauge comprehensibility and participant satisfaction, we included 3 questions dedicated to each aspect within the same set of 8 questions.</p><p><strong>Results: </strong>As of April 10, 2023, the 5 evaluator neurologists and 5 family members of patients with AD rated the 112 responses: GPT-3.5: n=28, 25%, responses; GPT-4: n=28, 25%, responses; respondent neurologists: 56 (50%) responses. The top 5 (4.5%) responses rated by evaluator neurologists had 4 (80%) GPT (GPT-3.5+GPT-4) responses and 1 (20%) respondent neurologist's response. For the top 5 (4.5%) responses rated by patients' family members, all but the third response were GPT responses. Based on the evaluation by neurologists, the neurologist-generated responses achieved a mean score of 3.9 (SD 0.7), while the GPT-generated responses scored significantly higher (mean 4.4, SD 0.6; P<.001). Language and model analyses revealed no significant differences in response quality between the GPT-3.5 and GPT-4 models (GPT-3.5: mean 4.3, SD 0.7; GPT-4: mean 4.4, SD 0.5; P=.51). However, English responses outperformed Chinese responses in terms of comprehensibility (Chinese responses: mean 4.1, SD 0.7; English responses: mean 4.6, SD 0.5; P=.005) and participant satisfaction (Chinese responses: mean 4.2, SD 0.8; English responses: mean 4.5, SD 0.5; P=.04). According to the evaluator neurologists' review, Chinese responses had a mean score of 4.4 (SD 0.6), whereas English responses had a mean score of 4.5 (SD 0.5; P=.002). As for the family members of patients with AD, no significant differences were observed between GPT and neurologists, GPT-3.5 and GPT-4, or Chinese and English responses.</p><p><strong>Conclusions: </strong>GPT can provide patient education materials on AD for patients, their families and caregivers, nurses, and neurologists. This capability can contribute to the effective health care management of patients with AD, leading to enhanced patient outcomes.</p>","PeriodicalId":16337,"journal":{"name":"Journal of Medical Internet Research","volume":"26 ","pages":"e51095"},"PeriodicalIF":6.0000,"publicationDate":"2024-10-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11565080/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Medical Internet Research","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/51095","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Alzheimer's disease (AD) is a progressive neurodegenerative disorder posing challenges to patients, caregivers, and society. Accessible and accurate information is crucial for effective AD management.
Objective: This study aimed to evaluate the accuracy, comprehensibility, clarity, and usefulness of the Generative Pretrained Transformer's (GPT) answers concerning the management and caregiving of patients with AD.
Methods: In total, 14 questions related to the prevention, treatment, and care of AD were identified and posed to GPT-3.5 and GPT-4 in Chinese and English, respectively, and 4 respondent neurologists were asked to answer them. We generated 8 sets of responses (total 112) and randomly coded them in answer sheets. Next, 5 evaluator neurologists and 5 family members of patients were asked to rate the 112 responses using separate 5-point Likert scales. We evaluated the quality of the responses using a set of 8 questions rated on a 5-point Likert scale. To gauge comprehensibility and participant satisfaction, we included 3 questions dedicated to each aspect within the same set of 8 questions.
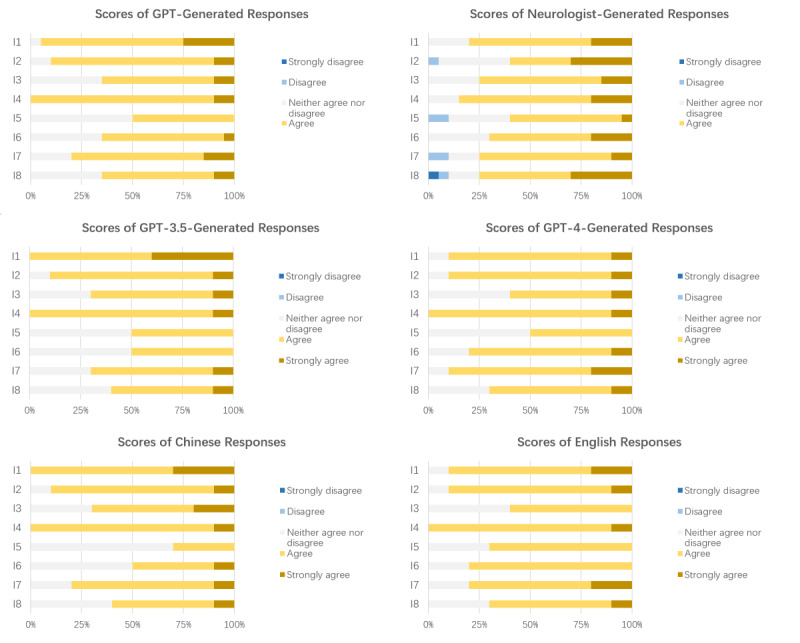
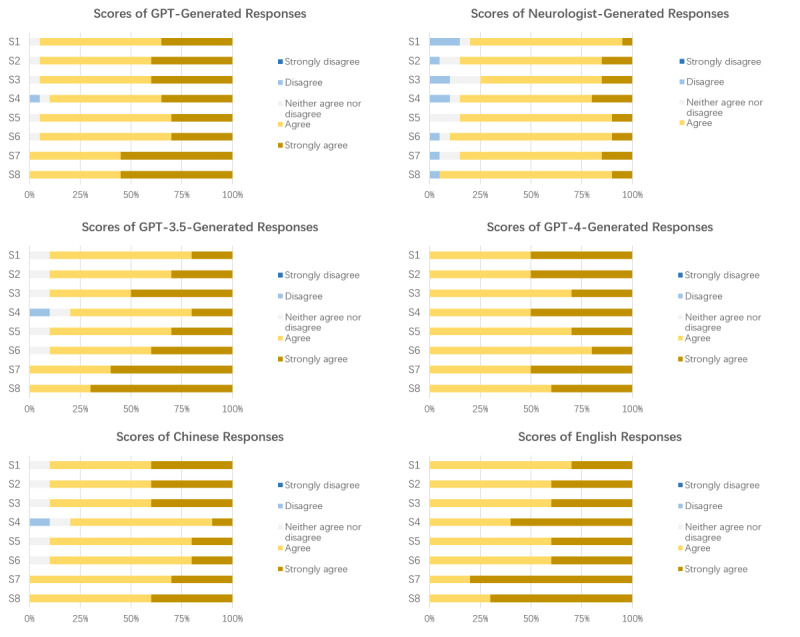
Results: As of April 10, 2023, the 5 evaluator neurologists and 5 family members of patients with AD rated the 112 responses: GPT-3.5: n=28, 25%, responses; GPT-4: n=28, 25%, responses; respondent neurologists: 56 (50%) responses. The top 5 (4.5%) responses rated by evaluator neurologists had 4 (80%) GPT (GPT-3.5+GPT-4) responses and 1 (20%) respondent neurologist's response. For the top 5 (4.5%) responses rated by patients' family members, all but the third response were GPT responses. Based on the evaluation by neurologists, the neurologist-generated responses achieved a mean score of 3.9 (SD 0.7), while the GPT-generated responses scored significantly higher (mean 4.4, SD 0.6; P<.001). Language and model analyses revealed no significant differences in response quality between the GPT-3.5 and GPT-4 models (GPT-3.5: mean 4.3, SD 0.7; GPT-4: mean 4.4, SD 0.5; P=.51). However, English responses outperformed Chinese responses in terms of comprehensibility (Chinese responses: mean 4.1, SD 0.7; English responses: mean 4.6, SD 0.5; P=.005) and participant satisfaction (Chinese responses: mean 4.2, SD 0.8; English responses: mean 4.5, SD 0.5; P=.04). According to the evaluator neurologists' review, Chinese responses had a mean score of 4.4 (SD 0.6), whereas English responses had a mean score of 4.5 (SD 0.5; P=.002). As for the family members of patients with AD, no significant differences were observed between GPT and neurologists, GPT-3.5 and GPT-4, or Chinese and English responses.
Conclusions: GPT can provide patient education materials on AD for patients, their families and caregivers, nurses, and neurologists. This capability can contribute to the effective health care management of patients with AD, leading to enhanced patient outcomes.
期刊介绍:
The Journal of Medical Internet Research (JMIR) is a highly respected publication in the field of health informatics and health services. With a founding date in 1999, JMIR has been a pioneer in the field for over two decades.
As a leader in the industry, the journal focuses on digital health, data science, health informatics, and emerging technologies for health, medicine, and biomedical research. It is recognized as a top publication in these disciplines, ranking in the first quartile (Q1) by Impact Factor.
Notably, JMIR holds the prestigious position of being ranked #1 on Google Scholar within the "Medical Informatics" discipline.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
