Pedro Esteban Chavarrias Solano , Andrew Bulpitt , Venkataraman Subramanian , Sharib Ali
{"title":"Multi-task learning with cross-task consistency for improved depth estimation in colonoscopy","authors":"Pedro Esteban Chavarrias Solano , Andrew Bulpitt , Venkataraman Subramanian , Sharib Ali","doi":"10.1016/j.media.2024.103379","DOIUrl":null,"url":null,"abstract":"<div><div>Colonoscopy screening is the gold standard procedure for assessing abnormalities in the colon and rectum, such as ulcers and cancerous polyps. Measuring the abnormal mucosal area and its 3D reconstruction can help quantify the surveyed area and objectively evaluate disease burden. However, due to the complex topology of these organs and variable physical conditions, for example, lighting, large homogeneous texture, and image modality estimating distance from the camera (<em>aka</em> depth) is highly challenging. Moreover, most colonoscopic video acquisition is monocular, making the depth estimation a non-trivial problem. While methods in computer vision for depth estimation have been proposed and advanced on natural scene datasets, the efficacy of these techniques has not been widely quantified on colonoscopy datasets. As the colonic mucosa has several low-texture regions that are not well pronounced, learning representations from an auxiliary task can improve salient feature extraction, allowing estimation of accurate camera depths. In this work, we propose to develop a novel multi-task learning (MTL) approach with a shared encoder and two decoders, namely a surface normal decoder and a depth estimator decoder. Our depth estimator incorporates attention mechanisms to enhance global context awareness. We leverage the surface normal prediction to improve geometric feature extraction. Also, we apply a cross-task consistency loss among the two geometrically related tasks, surface normal and camera depth. We demonstrate an improvement of 15.75% on relative error and 10.7% improvement on <span><math><msub><mrow><mi>δ</mi></mrow><mrow><mn>1</mn><mo>.</mo><mn>25</mn></mrow></msub></math></span> accuracy over the most accurate baseline state-of-the-art Big-to-Small (BTS) approach. All experiments are conducted on a recently released C3VD dataset, and thus, we provide a first benchmark of state-of-the-art methods on this dataset.</div></div>","PeriodicalId":18328,"journal":{"name":"Medical image analysis","volume":"99 ","pages":"Article 103379"},"PeriodicalIF":11.8000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Medical image analysis","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1361841524003049","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/4 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
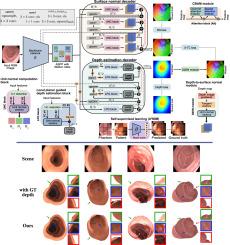
Colonoscopy screening is the gold standard procedure for assessing abnormalities in the colon and rectum, such as ulcers and cancerous polyps. Measuring the abnormal mucosal area and its 3D reconstruction can help quantify the surveyed area and objectively evaluate disease burden. However, due to the complex topology of these organs and variable physical conditions, for example, lighting, large homogeneous texture, and image modality estimating distance from the camera (aka depth) is highly challenging. Moreover, most colonoscopic video acquisition is monocular, making the depth estimation a non-trivial problem. While methods in computer vision for depth estimation have been proposed and advanced on natural scene datasets, the efficacy of these techniques has not been widely quantified on colonoscopy datasets. As the colonic mucosa has several low-texture regions that are not well pronounced, learning representations from an auxiliary task can improve salient feature extraction, allowing estimation of accurate camera depths. In this work, we propose to develop a novel multi-task learning (MTL) approach with a shared encoder and two decoders, namely a surface normal decoder and a depth estimator decoder. Our depth estimator incorporates attention mechanisms to enhance global context awareness. We leverage the surface normal prediction to improve geometric feature extraction. Also, we apply a cross-task consistency loss among the two geometrically related tasks, surface normal and camera depth. We demonstrate an improvement of 15.75% on relative error and 10.7% improvement on accuracy over the most accurate baseline state-of-the-art Big-to-Small (BTS) approach. All experiments are conducted on a recently released C3VD dataset, and thus, we provide a first benchmark of state-of-the-art methods on this dataset.
期刊介绍:
Medical Image Analysis serves as a platform for sharing new research findings in the realm of medical and biological image analysis, with a focus on applications of computer vision, virtual reality, and robotics to biomedical imaging challenges. The journal prioritizes the publication of high-quality, original papers contributing to the fundamental science of processing, analyzing, and utilizing medical and biological images. It welcomes approaches utilizing biomedical image datasets across all spatial scales, from molecular/cellular imaging to tissue/organ imaging.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
