{"title":"Enhancing semantic mapping in text-to-image diffusion via Gather-and-Bind","authors":"Huan Fu, Guoqing Cheng","doi":"10.1016/j.cag.2024.104118","DOIUrl":null,"url":null,"abstract":"<div><div>Text-to-image synthesis is a challenging task that aims to generate realistic and diverse images from natural language descriptions. However, existing text-to-image diffusion models (e.g., Stable Diffusion) sometimes fail to satisfy the semantic descriptions of the users, especially when the prompts contain multiple concepts or modifiers such as colors. By visualizing the cross-attention maps of the Stable Diffusion model during the denoising process, we find that one of the concepts has a very scattered attention map, which cannot form a whole and gradually gets ignored. Moreover, the attention maps of the modifiers are hard to overlap with the corresponding concepts, resulting in incorrect semantic mapping. To address this issue, we propose a Gather-and-Bind method that intervenes in the cross-attention maps during the denoising process to alleviate the catastrophic forgetting and attribute binding problems without any pre-training. Specifically, we first use information entropy to measure the dispersion degree of the cross-attention maps and construct an information entropy loss to gather these scattered attention maps, which eventually captures all the concepts in the generated output. Furthermore, we construct an attribute binding loss that minimizes the distance between the attention maps of the attributes and their corresponding concepts, which enables the model to establish correct semantic mapping and significantly improves the performance of the baseline model. We conduct extensive experiments on public datasets and demonstrate that our method can better capture the semantic information of the input prompts. Code is available at <span><span>https://github.com/huan085128/Gather-and-Bind</span><svg><path></path></svg></span>.</div></div>","PeriodicalId":50628,"journal":{"name":"Computers & Graphics-Uk","volume":"125 ","pages":"Article 104118"},"PeriodicalIF":2.8000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computers & Graphics-Uk","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S009784932400253X","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/7 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
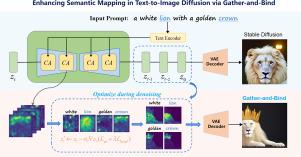
Text-to-image synthesis is a challenging task that aims to generate realistic and diverse images from natural language descriptions. However, existing text-to-image diffusion models (e.g., Stable Diffusion) sometimes fail to satisfy the semantic descriptions of the users, especially when the prompts contain multiple concepts or modifiers such as colors. By visualizing the cross-attention maps of the Stable Diffusion model during the denoising process, we find that one of the concepts has a very scattered attention map, which cannot form a whole and gradually gets ignored. Moreover, the attention maps of the modifiers are hard to overlap with the corresponding concepts, resulting in incorrect semantic mapping. To address this issue, we propose a Gather-and-Bind method that intervenes in the cross-attention maps during the denoising process to alleviate the catastrophic forgetting and attribute binding problems without any pre-training. Specifically, we first use information entropy to measure the dispersion degree of the cross-attention maps and construct an information entropy loss to gather these scattered attention maps, which eventually captures all the concepts in the generated output. Furthermore, we construct an attribute binding loss that minimizes the distance between the attention maps of the attributes and their corresponding concepts, which enables the model to establish correct semantic mapping and significantly improves the performance of the baseline model. We conduct extensive experiments on public datasets and demonstrate that our method can better capture the semantic information of the input prompts. Code is available at https://github.com/huan085128/Gather-and-Bind.
期刊介绍:
Computers & Graphics is dedicated to disseminate information on research and applications of computer graphics (CG) techniques. The journal encourages articles on:
1. Research and applications of interactive computer graphics. We are particularly interested in novel interaction techniques and applications of CG to problem domains.
2. State-of-the-art papers on late-breaking, cutting-edge research on CG.
3. Information on innovative uses of graphics principles and technologies.
4. Tutorial papers on both teaching CG principles and innovative uses of CG in education.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
