Lydia A. Schoenpflug , Yao Nie , Fahime Sheikhzadeh , Viktor H. Koelzer
{"title":"A review on federated learning in computational pathology","authors":"Lydia A. Schoenpflug , Yao Nie , Fahime Sheikhzadeh , Viktor H. Koelzer","doi":"10.1016/j.csbj.2024.10.037","DOIUrl":null,"url":null,"abstract":"<div><div>Training generalizable computational pathology (CPATH) algorithms is heavily dependent on large-scale, multi-institutional data. Simultaneously, healthcare data underlies strict data privacy rules, hindering the creation of large datasets. Federated Learning (FL) is a paradigm addressing this dilemma, by allowing separate institutions to collaborate in a training process while keeping each institution's data private and exchanging model parameters instead. In this study, we identify and review key developments of FL for CPATH applications. We consider 15 studies, thereby evaluating the current status of exploring and adapting this emerging technology for CPATH applications. Proof-of-concept studies have been conducted across a wide range of CPATH use cases, showcasing the performance equivalency of models trained in a federated compared to a centralized manner. Six studies focus on model aggregation or model alignment methods reporting minor (<span><math><mn>0</mn><mo>∼</mo><mn>3</mn><mtext>%</mtext></math></span>) performance improvement compared to conventional FL techniques, while four studies explore domain alignment methods, resulting in more significant performance improvements (<span><math><mn>4</mn><mo>∼</mo><mn>20</mn><mtext>%</mtext></math></span>). To further reduce the privacy risk posed by sharing model parameters, four studies investigated the use of privacy preservation methods, where all methods demonstrated equivalent or slightly degraded performance (<span><math><mn>0.2</mn><mo>∼</mo><mn>6</mn><mtext>%</mtext></math></span> lower). To facilitate broader, real-world environment adoption, it is imperative to establish guidelines for the setup and deployment of FL infrastructure, alongside the promotion of standardized software frameworks. These steps are crucial to 1) further democratize CPATH research by allowing smaller institutions to pool data and computational resources 2) investigating rare diseases, 3) conducting multi-institutional studies, and 4) allowing rapid prototyping on private data.</div></div>","PeriodicalId":10715,"journal":{"name":"Computational and structural biotechnology journal","volume":"23 ","pages":"Pages 3938-3945"},"PeriodicalIF":4.1000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational and structural biotechnology journal","FirstCategoryId":"99","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S200103702400357X","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/29 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
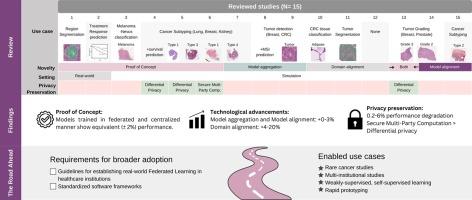
Training generalizable computational pathology (CPATH) algorithms is heavily dependent on large-scale, multi-institutional data. Simultaneously, healthcare data underlies strict data privacy rules, hindering the creation of large datasets. Federated Learning (FL) is a paradigm addressing this dilemma, by allowing separate institutions to collaborate in a training process while keeping each institution's data private and exchanging model parameters instead. In this study, we identify and review key developments of FL for CPATH applications. We consider 15 studies, thereby evaluating the current status of exploring and adapting this emerging technology for CPATH applications. Proof-of-concept studies have been conducted across a wide range of CPATH use cases, showcasing the performance equivalency of models trained in a federated compared to a centralized manner. Six studies focus on model aggregation or model alignment methods reporting minor () performance improvement compared to conventional FL techniques, while four studies explore domain alignment methods, resulting in more significant performance improvements (). To further reduce the privacy risk posed by sharing model parameters, four studies investigated the use of privacy preservation methods, where all methods demonstrated equivalent or slightly degraded performance ( lower). To facilitate broader, real-world environment adoption, it is imperative to establish guidelines for the setup and deployment of FL infrastructure, alongside the promotion of standardized software frameworks. These steps are crucial to 1) further democratize CPATH research by allowing smaller institutions to pool data and computational resources 2) investigating rare diseases, 3) conducting multi-institutional studies, and 4) allowing rapid prototyping on private data.
期刊介绍:
Computational and Structural Biotechnology Journal (CSBJ) is an online gold open access journal publishing research articles and reviews after full peer review. All articles are published, without barriers to access, immediately upon acceptance. The journal places a strong emphasis on functional and mechanistic understanding of how molecular components in a biological process work together through the application of computational methods. Structural data may provide such insights, but they are not a pre-requisite for publication in the journal. Specific areas of interest include, but are not limited to:
Structure and function of proteins, nucleic acids and other macromolecules
Structure and function of multi-component complexes
Protein folding, processing and degradation
Enzymology
Computational and structural studies of plant systems
Microbial Informatics
Genomics
Proteomics
Metabolomics
Algorithms and Hypothesis in Bioinformatics
Mathematical and Theoretical Biology
Computational Chemistry and Drug Discovery
Microscopy and Molecular Imaging
Nanotechnology
Systems and Synthetic Biology



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
