Mitja Briscik, Gabriele Tazza, László Vidács, Marie-Agnès Dillies, Sébastien Déjean
{"title":"Supervised multiple kernel learning approaches for multi-omics data integration.","authors":"Mitja Briscik, Gabriele Tazza, László Vidács, Marie-Agnès Dillies, Sébastien Déjean","doi":"10.1186/s13040-024-00406-9","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Advances in high-throughput technologies have originated an ever-increasing availability of omics datasets. The integration of multiple heterogeneous data sources is currently an issue for biology and bioinformatics. Multiple kernel learning (MKL) has shown to be a flexible and valid approach to consider the diverse nature of multi-omics inputs, despite being an underused tool in genomic data mining.</p><p><strong>Results: </strong>We provide novel MKL approaches based on different kernel fusion strategies. To learn from the meta-kernel of input kernels, we adapted unsupervised integration algorithms for supervised tasks with support vector machines. We also tested deep learning architectures for kernel fusion and classification. The results show that MKL-based models can outperform more complex, state-of-the-art, supervised multi-omics integrative approaches.</p><p><strong>Conclusion: </strong>Multiple kernel learning offers a natural framework for predictive models in multi-omics data. It proved to provide a fast and reliable solution that can compete with and outperform more complex architectures. Our results offer a direction for bio-data mining research, biomarker discovery and further development of methods for heterogeneous data integration.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"17 1","pages":"53"},"PeriodicalIF":6.1000,"publicationDate":"2024-11-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11585117/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-024-00406-9","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Advances in high-throughput technologies have originated an ever-increasing availability of omics datasets. The integration of multiple heterogeneous data sources is currently an issue for biology and bioinformatics. Multiple kernel learning (MKL) has shown to be a flexible and valid approach to consider the diverse nature of multi-omics inputs, despite being an underused tool in genomic data mining.
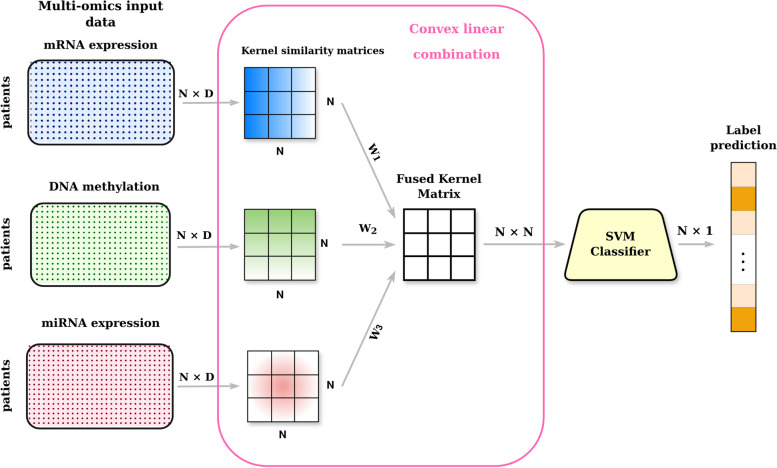
Results: We provide novel MKL approaches based on different kernel fusion strategies. To learn from the meta-kernel of input kernels, we adapted unsupervised integration algorithms for supervised tasks with support vector machines. We also tested deep learning architectures for kernel fusion and classification. The results show that MKL-based models can outperform more complex, state-of-the-art, supervised multi-omics integrative approaches.
Conclusion: Multiple kernel learning offers a natural framework for predictive models in multi-omics data. It proved to provide a fast and reliable solution that can compete with and outperform more complex architectures. Our results offer a direction for bio-data mining research, biomarker discovery and further development of methods for heterogeneous data integration.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
