Zhengxin Li , Chongzhen Tian , Hui Yuan , Xin Lu , Hossein Malekmohamadi
{"title":"3D-MSFC: A 3D multi-scale features compression method for object detection","authors":"Zhengxin Li , Chongzhen Tian , Hui Yuan , Xin Lu , Hossein Malekmohamadi","doi":"10.1016/j.displa.2024.102880","DOIUrl":null,"url":null,"abstract":"<div><div>As machine vision tasks rapidly evolve, a new concept of compression, namely video coding for machines (VCM), has emerged. However, current VCM methods are only suitable for 2D machine vision tasks. With the popularization of autonomous driving, the demand for 3D machine vision tasks has significantly increased, leading to an explosive growth in LiDAR data that requires efficient transmission. To address this need, we propose a machine vision-based point cloud coding paradigm inspired by VCM. Specifically, we introduce a 3D multi-scale features compression (3D-MSFC) method, tailored for 3D object detection. Experimental results demonstrate that 3D-MSFC achieves less than a 3% degradation in object detection accuracy at a compression ratio of 2796<span><math><mo>×</mo></math></span>. Furthermore, its low-profile variant, 3D-MSFC-L, achieves less than a 2% degradation in accuracy at a compression ratio of 463<span><math><mo>×</mo></math></span>. The above results indicate that our proposed method can provide an ultra-high compression ratio while ensuring no significant drop in accuracy, greatly reducing the amount of data required for transmission during each detection. This can significantly lower bandwidth consumption and save substantial costs in application scenarios such as smart cities.</div></div>","PeriodicalId":50570,"journal":{"name":"Displays","volume":"85 ","pages":"Article 102880"},"PeriodicalIF":3.4000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Displays","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0141938224002440","RegionNum":2,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/17 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE","Score":null,"Total":0}
引用次数: 0
Abstract
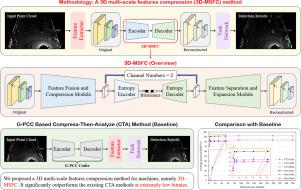
As machine vision tasks rapidly evolve, a new concept of compression, namely video coding for machines (VCM), has emerged. However, current VCM methods are only suitable for 2D machine vision tasks. With the popularization of autonomous driving, the demand for 3D machine vision tasks has significantly increased, leading to an explosive growth in LiDAR data that requires efficient transmission. To address this need, we propose a machine vision-based point cloud coding paradigm inspired by VCM. Specifically, we introduce a 3D multi-scale features compression (3D-MSFC) method, tailored for 3D object detection. Experimental results demonstrate that 3D-MSFC achieves less than a 3% degradation in object detection accuracy at a compression ratio of 2796. Furthermore, its low-profile variant, 3D-MSFC-L, achieves less than a 2% degradation in accuracy at a compression ratio of 463. The above results indicate that our proposed method can provide an ultra-high compression ratio while ensuring no significant drop in accuracy, greatly reducing the amount of data required for transmission during each detection. This can significantly lower bandwidth consumption and save substantial costs in application scenarios such as smart cities.
期刊介绍:
Displays is the international journal covering the research and development of display technology, its effective presentation and perception of information, and applications and systems including display-human interface.
Technical papers on practical developments in Displays technology provide an effective channel to promote greater understanding and cross-fertilization across the diverse disciplines of the Displays community. Original research papers solving ergonomics issues at the display-human interface advance effective presentation of information. Tutorial papers covering fundamentals intended for display technologies and human factor engineers new to the field will also occasionally featured.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
