Large language model doctor: assessing the ability of ChatGPT-4 to deliver interventional radiology procedural information to patients during the consent process.
{"title":"Large language model doctor: assessing the ability of ChatGPT-4 to deliver interventional radiology procedural information to patients during the consent process.","authors":"Hayden L Hofmann, Jenanan Vairavamurthy","doi":"10.1186/s42155-024-00477-z","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>The study aims to evaluate how current interventional radiologists view ChatGPT in the context of informed consent for interventional radiology (IR) procedures.</p><p><strong>Methods: </strong>ChatGPT-4 was instructed to outline the risks, benefits, and alternatives for IR procedures. The outputs were reviewed by IR physicians to assess if outputs were 1) accurate, 2) comprehensive, 3) easy to understand, 4) written in a conversational tone, and 5) if they were comfortable providing the output to the patient. For each criterion, outputs were measured on a 5-point scale. Mean scores and percentage of physicians rating output as sufficient (4 or 5 on 5-point scale) were measured. A linear regression correlated mean rating with number of years in practice. Intraclass correlation coefficient (ICC) measured agreement among physicians.</p><p><strong>Results: </strong>The mean rating of the ChatGPT responses was 4.29, 3.85, 4.15, 4.24, 3.82 for accuracy, comprehensiveness, readability, conversational tone, and physician comfort level, respectively. Percentage of physicians rating outputs as sufficient was 84%, 71%, 85%, 85%, and 67% for accuracy, comprehensiveness, readability, conversational tone, and physician comfort level, respectively. There was an inverse relationship between years in training and output score (coeff = -0.03413, p = 0.0128); ICC measured 0.39 (p = 0.003).</p><p><strong>Conclusions: </strong>GPT-4 produced outputs that were accurate, understandable, and in a conversational tone. However, GPT-4 had a decreased capacity to produce a comprehensive output leading some physicians to be uncomfortable providing the output to patients. Practicing IRs should be aware of these limitations when counseling patients as ChatGPT-4 continues to develop into a clinically usable AI tool.</p>","PeriodicalId":52351,"journal":{"name":"CVIR Endovascular","volume":"7 1","pages":"83"},"PeriodicalIF":1.5000,"publicationDate":"2024-11-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11607371/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"CVIR Endovascular","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s42155-024-00477-z","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"CARDIAC & CARDIOVASCULAR SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
Purpose: The study aims to evaluate how current interventional radiologists view ChatGPT in the context of informed consent for interventional radiology (IR) procedures.
Methods: ChatGPT-4 was instructed to outline the risks, benefits, and alternatives for IR procedures. The outputs were reviewed by IR physicians to assess if outputs were 1) accurate, 2) comprehensive, 3) easy to understand, 4) written in a conversational tone, and 5) if they were comfortable providing the output to the patient. For each criterion, outputs were measured on a 5-point scale. Mean scores and percentage of physicians rating output as sufficient (4 or 5 on 5-point scale) were measured. A linear regression correlated mean rating with number of years in practice. Intraclass correlation coefficient (ICC) measured agreement among physicians.
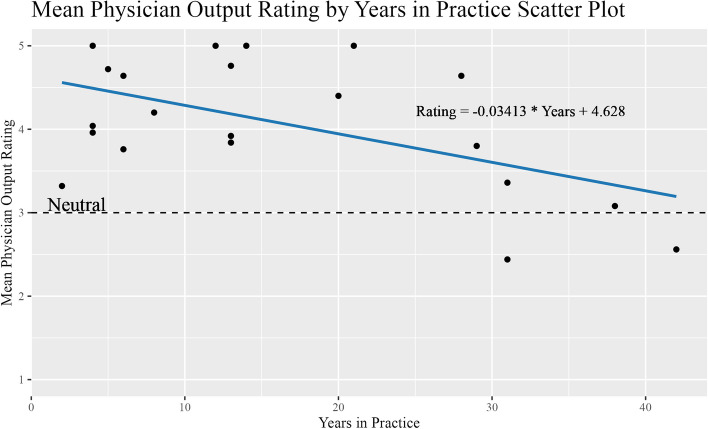
Results: The mean rating of the ChatGPT responses was 4.29, 3.85, 4.15, 4.24, 3.82 for accuracy, comprehensiveness, readability, conversational tone, and physician comfort level, respectively. Percentage of physicians rating outputs as sufficient was 84%, 71%, 85%, 85%, and 67% for accuracy, comprehensiveness, readability, conversational tone, and physician comfort level, respectively. There was an inverse relationship between years in training and output score (coeff = -0.03413, p = 0.0128); ICC measured 0.39 (p = 0.003).
Conclusions: GPT-4 produced outputs that were accurate, understandable, and in a conversational tone. However, GPT-4 had a decreased capacity to produce a comprehensive output leading some physicians to be uncomfortable providing the output to patients. Practicing IRs should be aware of these limitations when counseling patients as ChatGPT-4 continues to develop into a clinically usable AI tool.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
