{"title":"Performance of automated machine learning in detecting fundus diseases based on ophthalmologic B-scan ultrasound images.","authors":"Qiaoling Wei, Qian Chen, Chen Zhao, Rui Jiang","doi":"10.1136/bmjophth-2024-001873","DOIUrl":null,"url":null,"abstract":"<p><strong>Aim: </strong>To evaluate the efficacy of automated machine learning (AutoML) models in detecting fundus diseases using ocular B-scan ultrasound images.</p><p><strong>Methods: </strong>Ophthalmologists annotated two B-scan ultrasound image datasets to develop three AutoML models-single-label, multi-class single-label and multi-label-on the Vertex artificial intelligence (AI) platform. Performance of these models was compared among themselves and against existing bespoke models for binary classification tasks.</p><p><strong>Results: </strong>The training set involved 3938 images from 1378 patients, while batch predictions used an additional set of 336 images from 180 patients. The single-label AutoML model, trained on normal and abnormal fundus images, achieved an area under the precision-recall curve (AUPRC) of 0.9943. The multi-class single-label model, focused on single-pathology images, recorded an AUPRC of 0.9617, with performance metrics of these two single-label models proving comparable to those of previously published models. The multi-label model, designed to detect both single and multiple pathologies, posted an AUPRC of 0.9650. Pathology classification AUPRCs for the multi-class single-label model ranged from 0.9277 to 1.0000 and from 0.8780 to 0.9980 for the multi-label model. Batch prediction accuracies ranged from 86.57% to 97.65% for various fundus conditions in the multi-label AutoML model. Statistical analysis demonstrated that the single-label model significantly outperformed the other two models in all evaluated metrics (p<0.05).</p><p><strong>Conclusion: </strong>AutoML models, developed by clinicians, effectively detected multiple fundus lesions with performance on par with that of deep-learning models crafted by AI specialists. This underscores AutoML's potential to revolutionise ophthalmologic diagnostics, facilitating broader accessibility and application of sophisticated diagnostic technologies.</p>","PeriodicalId":9286,"journal":{"name":"BMJ Open Ophthalmology","volume":"9 1","pages":""},"PeriodicalIF":2.2000,"publicationDate":"2024-12-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11647328/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Open Ophthalmology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjophth-2024-001873","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"OPHTHALMOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Aim: To evaluate the efficacy of automated machine learning (AutoML) models in detecting fundus diseases using ocular B-scan ultrasound images.
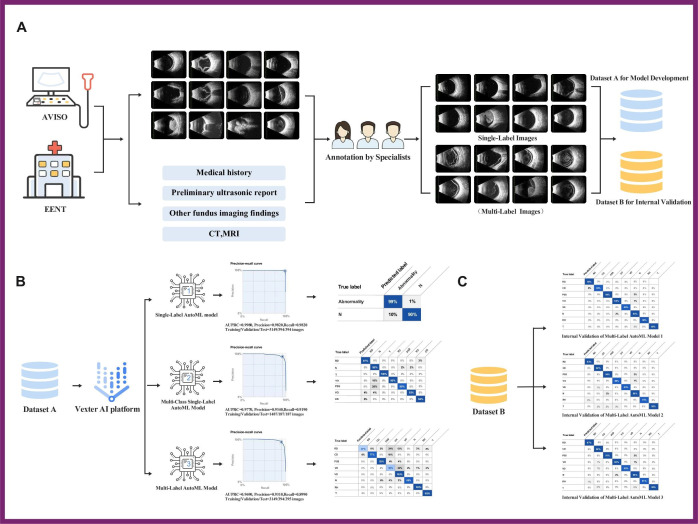
Methods: Ophthalmologists annotated two B-scan ultrasound image datasets to develop three AutoML models-single-label, multi-class single-label and multi-label-on the Vertex artificial intelligence (AI) platform. Performance of these models was compared among themselves and against existing bespoke models for binary classification tasks.
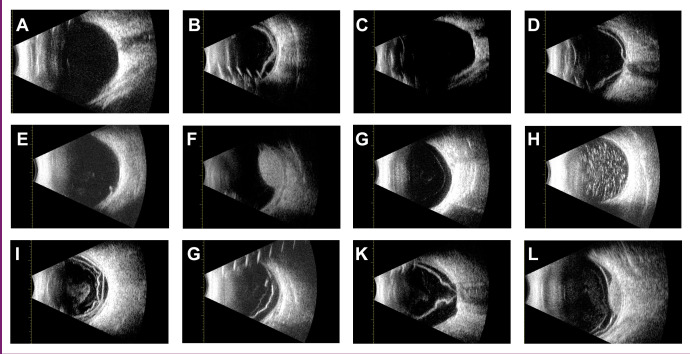
Results: The training set involved 3938 images from 1378 patients, while batch predictions used an additional set of 336 images from 180 patients. The single-label AutoML model, trained on normal and abnormal fundus images, achieved an area under the precision-recall curve (AUPRC) of 0.9943. The multi-class single-label model, focused on single-pathology images, recorded an AUPRC of 0.9617, with performance metrics of these two single-label models proving comparable to those of previously published models. The multi-label model, designed to detect both single and multiple pathologies, posted an AUPRC of 0.9650. Pathology classification AUPRCs for the multi-class single-label model ranged from 0.9277 to 1.0000 and from 0.8780 to 0.9980 for the multi-label model. Batch prediction accuracies ranged from 86.57% to 97.65% for various fundus conditions in the multi-label AutoML model. Statistical analysis demonstrated that the single-label model significantly outperformed the other two models in all evaluated metrics (p<0.05).
Conclusion: AutoML models, developed by clinicians, effectively detected multiple fundus lesions with performance on par with that of deep-learning models crafted by AI specialists. This underscores AutoML's potential to revolutionise ophthalmologic diagnostics, facilitating broader accessibility and application of sophisticated diagnostic technologies.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
