{"title":"Comparative evaluation of artificial intelligence systems' accuracy in providing medical drug dosages: A methodological study.","authors":"Swaminathan Ramasubramanian, Sangeetha Balaji, Tejashri Kannan, Naveen Jeyaraman, Shilpa Sharma, Filippo Migliorini, Suhasini Balasubramaniam, Madhan Jeyaraman","doi":"10.5662/wjm.v14.i4.92802","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Medication errors, especially in dosage calculation, pose risks in healthcare. Artificial intelligence (AI) systems like ChatGPT and Google Bard may help reduce errors, but their accuracy in providing medication information remains to be evaluated.</p><p><strong>Aim: </strong>To evaluate the accuracy of AI systems (ChatGPT 3.5, ChatGPT 4, Google Bard) in providing drug dosage information per Harrison's Principles of Internal Medicine.</p><p><strong>Methods: </strong>A set of natural language queries mimicking real-world medical dosage inquiries was presented to the AI systems. Responses were analyzed using a 3-point Likert scale. The analysis, conducted with Python and its libraries, focused on basic statistics, overall system accuracy, and disease-specific and organ system accuracies.</p><p><strong>Results: </strong>ChatGPT 4 outperformed the other systems, showing the highest rate of correct responses (83.77%) and the best overall weighted accuracy (0.6775). Disease-specific accuracy varied notably across systems, with some diseases being accurately recognized, while others demonstrated significant discrepancies. Organ system accuracy also showed variable results, underscoring system-specific strengths and weaknesses.</p><p><strong>Conclusion: </strong>ChatGPT 4 demonstrates superior reliability in medical dosage information, yet variations across diseases emphasize the need for ongoing improvements. These results highlight AI's potential in aiding healthcare professionals, urging continuous development for dependable accuracy in critical medical situations.</p>","PeriodicalId":94271,"journal":{"name":"World journal of methodology","volume":"14 4","pages":"92802"},"PeriodicalIF":0.0000,"publicationDate":"2024-12-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11287534/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"World journal of methodology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.5662/wjm.v14.i4.92802","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Medication errors, especially in dosage calculation, pose risks in healthcare. Artificial intelligence (AI) systems like ChatGPT and Google Bard may help reduce errors, but their accuracy in providing medication information remains to be evaluated.
Aim: To evaluate the accuracy of AI systems (ChatGPT 3.5, ChatGPT 4, Google Bard) in providing drug dosage information per Harrison's Principles of Internal Medicine.
Methods: A set of natural language queries mimicking real-world medical dosage inquiries was presented to the AI systems. Responses were analyzed using a 3-point Likert scale. The analysis, conducted with Python and its libraries, focused on basic statistics, overall system accuracy, and disease-specific and organ system accuracies.
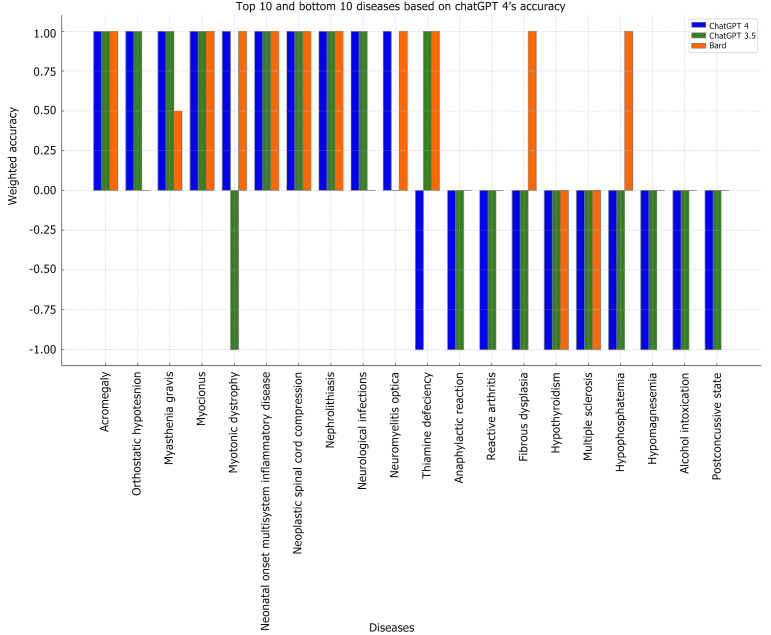
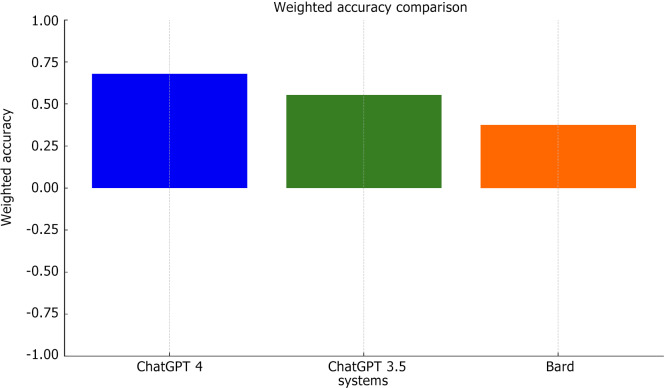
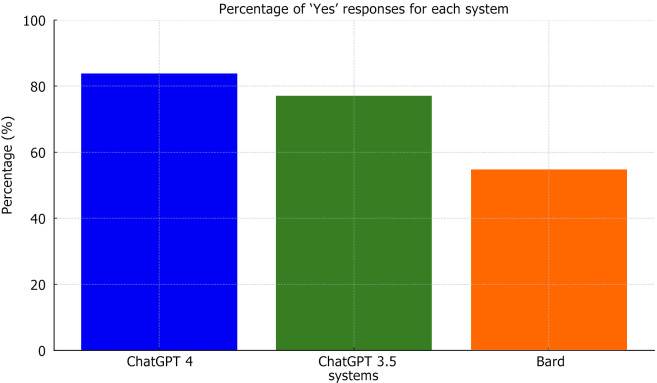
Results: ChatGPT 4 outperformed the other systems, showing the highest rate of correct responses (83.77%) and the best overall weighted accuracy (0.6775). Disease-specific accuracy varied notably across systems, with some diseases being accurately recognized, while others demonstrated significant discrepancies. Organ system accuracy also showed variable results, underscoring system-specific strengths and weaknesses.
Conclusion: ChatGPT 4 demonstrates superior reliability in medical dosage information, yet variations across diseases emphasize the need for ongoing improvements. These results highlight AI's potential in aiding healthcare professionals, urging continuous development for dependable accuracy in critical medical situations.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
