Ting Gao, Xue Zhai, Chuan Yang, Linlin Lv, Han Wang
{"title":"Joint extraction of entity and relation based on fine-tuning BERT for long biomedical literatures.","authors":"Ting Gao, Xue Zhai, Chuan Yang, Linlin Lv, Han Wang","doi":"10.1093/bioadv/vbae194","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Joint extraction of entity and relation is an important research direction in Information Extraction. The number of scientific and technological biomedical literature is rapidly increasing, so automatically extracting entities and their relations from these literatures are key tasks to promote the progress of biomedical research.</p><p><strong>Results: </strong>The joint extraction of entity and relation model achieves both intra-sentence extraction and cross-sentence extraction, alleviating the problem of long-distance information dependence in long literature. Joint extraction of entity and relation model incorporates a variety of advanced deep learning techniques in this paper: (i) a fine-tuning BERT text classification pre-training model, (ii) Graph Convolutional Network learning method, (iii) Robust Learning Against Textual Label Noise with Self-Mixup Training, (iv) Local regularization Conditional Random Fields. The model implements the following functions: identifying entities from complex biomedical literature effectively, extracting triples within and across sentences, reducing the effect of noisy data during training, and improving the robustness and accuracy of the model. The experiment results prove that the model performs well on the self-built BM_GBD dataset and public datasets, enabling precise large language model enhanced knowledge graph construction for biomedical tasks.</p><p><strong>Availability and implementation: </strong>The model and partial code are available on GitHub at https://github.com/zhaix922/Joint-extraction-of-entity-and-relation.</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"4 1","pages":"vbae194"},"PeriodicalIF":2.8000,"publicationDate":"2024-12-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11665630/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbae194","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
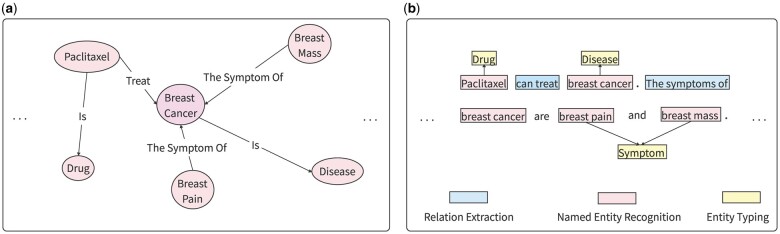
Motivation: Joint extraction of entity and relation is an important research direction in Information Extraction. The number of scientific and technological biomedical literature is rapidly increasing, so automatically extracting entities and their relations from these literatures are key tasks to promote the progress of biomedical research.
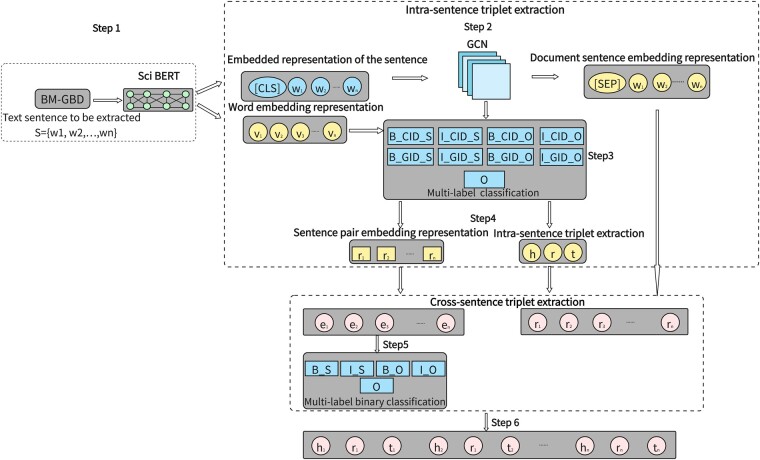
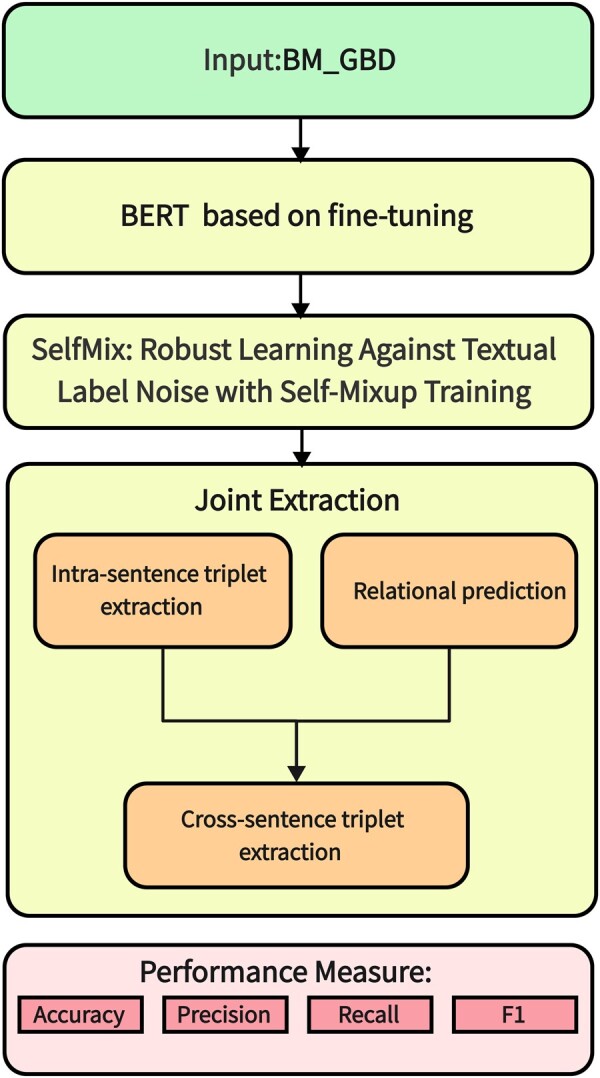
Results: The joint extraction of entity and relation model achieves both intra-sentence extraction and cross-sentence extraction, alleviating the problem of long-distance information dependence in long literature. Joint extraction of entity and relation model incorporates a variety of advanced deep learning techniques in this paper: (i) a fine-tuning BERT text classification pre-training model, (ii) Graph Convolutional Network learning method, (iii) Robust Learning Against Textual Label Noise with Self-Mixup Training, (iv) Local regularization Conditional Random Fields. The model implements the following functions: identifying entities from complex biomedical literature effectively, extracting triples within and across sentences, reducing the effect of noisy data during training, and improving the robustness and accuracy of the model. The experiment results prove that the model performs well on the self-built BM_GBD dataset and public datasets, enabling precise large language model enhanced knowledge graph construction for biomedical tasks.
Availability and implementation: The model and partial code are available on GitHub at https://github.com/zhaix922/Joint-extraction-of-entity-and-relation.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
