Vasileios Ntinopoulos, Hector Rodriguez Cetina Biefer, Igor Tudorache, Nestoras Papadopoulos, Dragan Odavic, Petar Risteski, Achim Haeussler, Omer Dzemali
{"title":"Large language models for data extraction from unstructured and semi-structured electronic health records: a multiple model performance evaluation.","authors":"Vasileios Ntinopoulos, Hector Rodriguez Cetina Biefer, Igor Tudorache, Nestoras Papadopoulos, Dragan Odavic, Petar Risteski, Achim Haeussler, Omer Dzemali","doi":"10.1136/bmjhci-2024-101139","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>We aimed to evaluate the performance of multiple large language models (LLMs) in data extraction from unstructured and semi-structured electronic health records.</p><p><strong>Methods: </strong>50 synthetic medical notes in English, containing a structured and an unstructured part, were drafted and evaluated by domain experts, and subsequently used for LLM-prompting. 18 LLMs were evaluated against a baseline transformer-based model. Performance assessment comprised four entity extraction and five binary classification tasks with a total of 450 predictions for each LLM. LLM-response consistency assessment was performed over three same-prompt iterations.</p><p><strong>Results: </strong>Claude 3.0 Opus, Claude 3.0 Sonnet, Claude 2.0, GPT 4, Claude 2.1, Gemini Advanced, PaLM 2 chat-bison and Llama 3-70b exhibited an excellent overall accuracy >0.98 (0.995, 0.988, 0.988, 0.988, 0.986, 0.982, 0.982, and 0.982, respectively), significantly higher than the baseline RoBERTa model (0.742). Claude 2.0, Claude 2.1, Claude 3.0 Opus, PaLM 2 chat-bison, GPT 4, Claude 3.0 Sonnet and Llama 3-70b showed a marginally higher and Gemini Advanced a marginally lower multiple-run consistency than the baseline model RoBERTa (Krippendorff's alpha value 1, 0.998, 0.996, 0.996, 0.992, 0.991, 0.989, 0.988, and 0.985, respectively).</p><p><strong>Discussion: </strong>Claude 3.0 Opus, Claude 3.0 Sonnet, Claude 2.0, GPT 4, Claude 2.1, Gemini Advanced, PaLM 2 chat bison and Llama 3-70b performed the best, exhibiting outstanding performance in both entity extraction and binary classification, with highly consistent responses over multiple same-prompt iterations. Their use could leverage data for research and unburden healthcare professionals. Real-data analyses are warranted to confirm their performance in a real-world setting.</p><p><strong>Conclusion: </strong>Claude 3.0 Opus, Claude 3.0 Sonnet, Claude 2.0, GPT 4, Claude 2.1, Gemini Advanced, PaLM 2 chat-bison and Llama 3-70b seem to be able to reliably extract data from unstructured and semi-structured electronic health records. Further analyses using real data are warranted to confirm their performance in a real-world setting.</p>","PeriodicalId":9050,"journal":{"name":"BMJ Health & Care Informatics","volume":"32 1","pages":""},"PeriodicalIF":4.4000,"publicationDate":"2025-01-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11751965/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Health & Care Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjhci-2024-101139","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: We aimed to evaluate the performance of multiple large language models (LLMs) in data extraction from unstructured and semi-structured electronic health records.
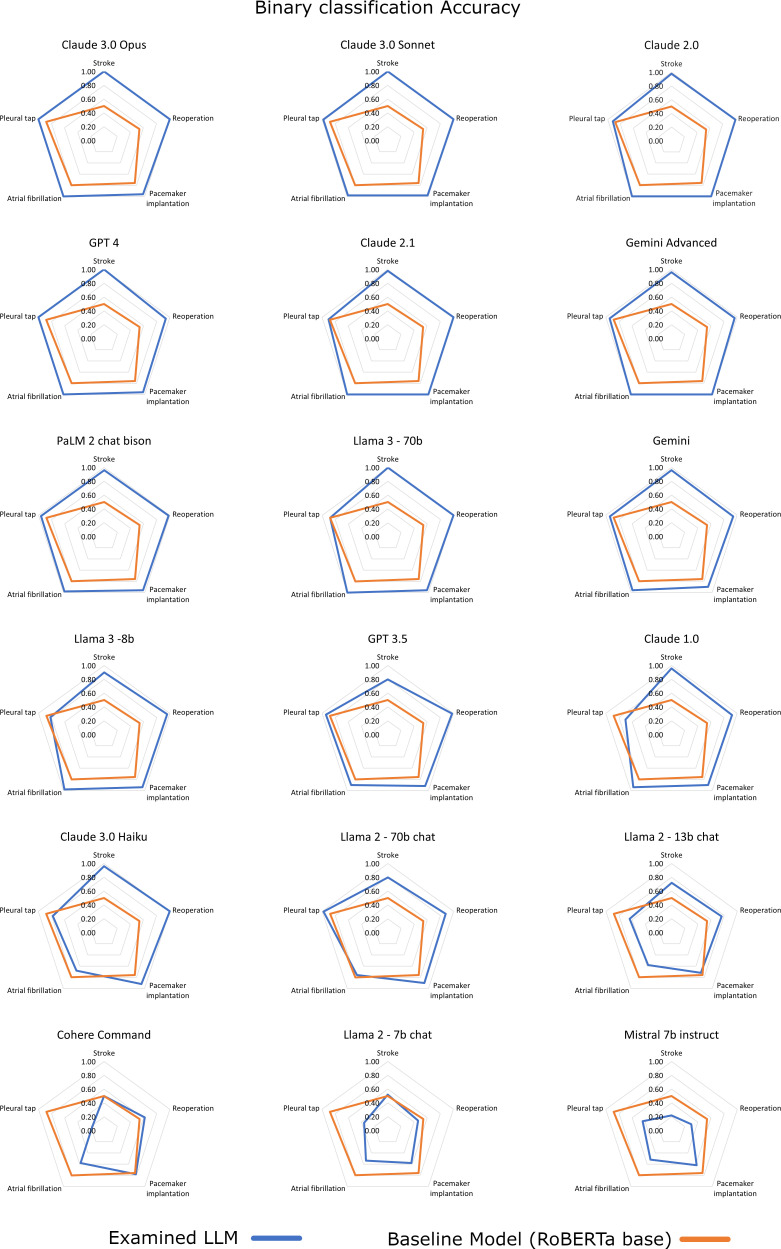
Methods: 50 synthetic medical notes in English, containing a structured and an unstructured part, were drafted and evaluated by domain experts, and subsequently used for LLM-prompting. 18 LLMs were evaluated against a baseline transformer-based model. Performance assessment comprised four entity extraction and five binary classification tasks with a total of 450 predictions for each LLM. LLM-response consistency assessment was performed over three same-prompt iterations.
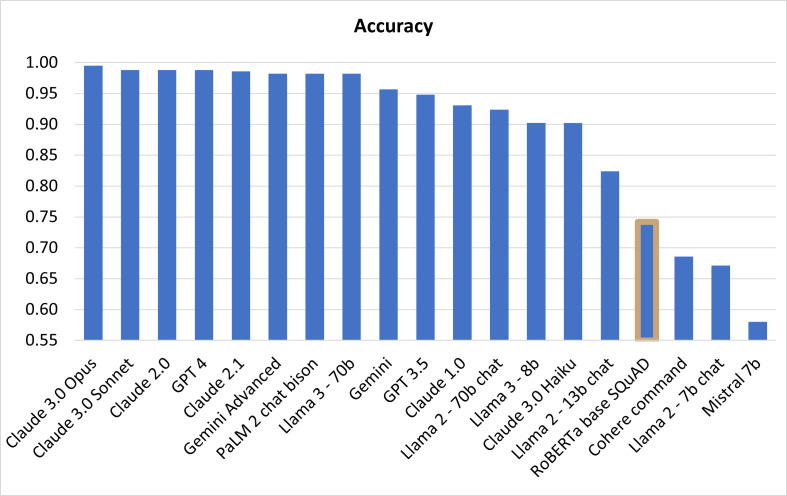
Results: Claude 3.0 Opus, Claude 3.0 Sonnet, Claude 2.0, GPT 4, Claude 2.1, Gemini Advanced, PaLM 2 chat-bison and Llama 3-70b exhibited an excellent overall accuracy >0.98 (0.995, 0.988, 0.988, 0.988, 0.986, 0.982, 0.982, and 0.982, respectively), significantly higher than the baseline RoBERTa model (0.742). Claude 2.0, Claude 2.1, Claude 3.0 Opus, PaLM 2 chat-bison, GPT 4, Claude 3.0 Sonnet and Llama 3-70b showed a marginally higher and Gemini Advanced a marginally lower multiple-run consistency than the baseline model RoBERTa (Krippendorff's alpha value 1, 0.998, 0.996, 0.996, 0.992, 0.991, 0.989, 0.988, and 0.985, respectively).
Discussion: Claude 3.0 Opus, Claude 3.0 Sonnet, Claude 2.0, GPT 4, Claude 2.1, Gemini Advanced, PaLM 2 chat bison and Llama 3-70b performed the best, exhibiting outstanding performance in both entity extraction and binary classification, with highly consistent responses over multiple same-prompt iterations. Their use could leverage data for research and unburden healthcare professionals. Real-data analyses are warranted to confirm their performance in a real-world setting.
Conclusion: Claude 3.0 Opus, Claude 3.0 Sonnet, Claude 2.0, GPT 4, Claude 2.1, Gemini Advanced, PaLM 2 chat-bison and Llama 3-70b seem to be able to reliably extract data from unstructured and semi-structured electronic health records. Further analyses using real data are warranted to confirm their performance in a real-world setting.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
