Semantic search helper: A tool based on the use of embeddings in multi-item questionnaires as a harmonization opportunity for merging large datasets - A feasibility study.
Karl Gottfried, Karina Janson, Nathalie E Holz, Olaf Reis, Johannes Kornhuber, Anna Eichler, Tobias Banaschewski, Frauke Nees
{"title":"Semantic search helper: A tool based on the use of embeddings in multi-item questionnaires as a harmonization opportunity for merging large datasets - A feasibility study.","authors":"Karl Gottfried, Karina Janson, Nathalie E Holz, Olaf Reis, Johannes Kornhuber, Anna Eichler, Tobias Banaschewski, Frauke Nees","doi":"10.1192/j.eurpsy.2024.1808","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Recent advances in natural language processing (NLP), particularly in language processing methods, have opened new avenues in semantic data analysis. A promising application of NLP is data harmonization in questionnaire-based cohort studies, where it can be used as an additional method, specifically when only different instruments are available for one construct as well as for the evaluation of potentially new construct-constellations. The present article therefore explores embedding models' potential to detect opportunities for semantic harmonization.</p><p><strong>Methods: </strong>Using models like SBERT and OpenAI's ADA, we developed a prototype application (\"Semantic Search Helper\") to facilitate the harmonization process of detecting semantically similar items within extensive health-related datasets. The approach's feasibility and applicability were evaluated through a use case analysis involving data from four large cohort studies with heterogeneous data obtained with a different set of instruments for common constructs.</p><p><strong>Results: </strong>With the prototype, we effectively identified potential harmonization pairs, which significantly reduced manual evaluation efforts. Expert ratings of semantic similarity candidates showed high agreement with model-generated pairs, confirming the validity of our approach.</p><p><strong>Conclusions: </strong>This study demonstrates the potential of embeddings in matching semantic similarity as a promising add-on tool to assist harmonization processes of multiplex data sets and instruments but with similar content, within and across studies.</p>","PeriodicalId":12155,"journal":{"name":"European Psychiatry","volume":"68 1","pages":"e8"},"PeriodicalIF":6.7000,"publicationDate":"2025-01-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11795448/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"European Psychiatry","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1192/j.eurpsy.2024.1808","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"PSYCHIATRY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Recent advances in natural language processing (NLP), particularly in language processing methods, have opened new avenues in semantic data analysis. A promising application of NLP is data harmonization in questionnaire-based cohort studies, where it can be used as an additional method, specifically when only different instruments are available for one construct as well as for the evaluation of potentially new construct-constellations. The present article therefore explores embedding models' potential to detect opportunities for semantic harmonization.
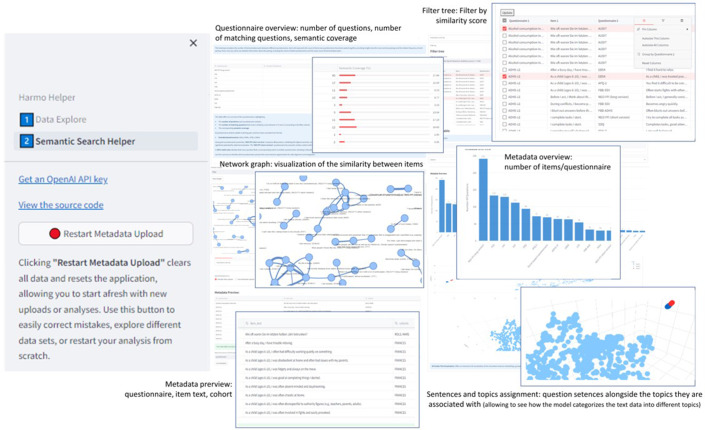
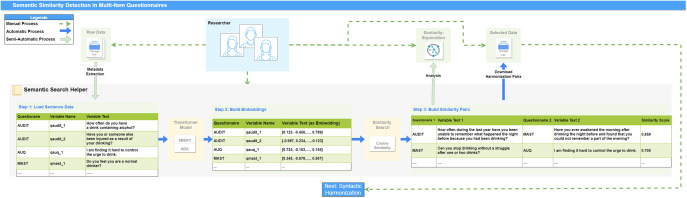
Methods: Using models like SBERT and OpenAI's ADA, we developed a prototype application ("Semantic Search Helper") to facilitate the harmonization process of detecting semantically similar items within extensive health-related datasets. The approach's feasibility and applicability were evaluated through a use case analysis involving data from four large cohort studies with heterogeneous data obtained with a different set of instruments for common constructs.
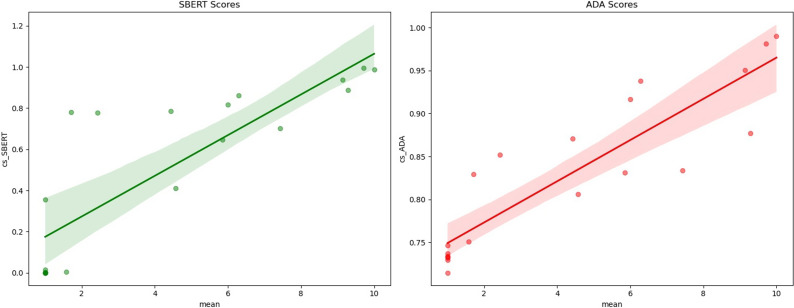
Results: With the prototype, we effectively identified potential harmonization pairs, which significantly reduced manual evaluation efforts. Expert ratings of semantic similarity candidates showed high agreement with model-generated pairs, confirming the validity of our approach.
Conclusions: This study demonstrates the potential of embeddings in matching semantic similarity as a promising add-on tool to assist harmonization processes of multiplex data sets and instruments but with similar content, within and across studies.
期刊介绍:
European Psychiatry, the official journal of the European Psychiatric Association, is dedicated to sharing cutting-edge research, policy updates, and fostering dialogue among clinicians, researchers, and patient advocates in the fields of psychiatry, mental health, behavioral science, and neuroscience. This peer-reviewed, Open Access journal strives to publish the latest advancements across various mental health issues, including diagnostic and treatment breakthroughs, as well as advancements in understanding the biological foundations of mental, behavioral, and cognitive functions in both clinical and general population studies.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
