Evaluating and Enhancing Japanese Large Language Models for Genetic Counseling Support: Comparative Study of Domain Adaptation and the Development of an Expert-Evaluated Dataset.
{"title":"Evaluating and Enhancing Japanese Large Language Models for Genetic Counseling Support: Comparative Study of Domain Adaptation and the Development of an Expert-Evaluated Dataset.","authors":"Takuya Fukushima, Masae Manabe, Shuntaro Yada, Shoko Wakamiya, Akiko Yoshida, Yusaku Urakawa, Akiko Maeda, Shigeyuki Kan, Masayo Takahashi, Eiji Aramaki","doi":"10.2196/65047","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Advances in genetics have underscored a strong association between genetic factors and health outcomes, leading to an increased demand for genetic counseling services. However, a shortage of qualified genetic counselors poses a significant challenge. Large language models (LLMs) have emerged as a potential solution for augmenting support in genetic counseling tasks. Despite the potential, Japanese genetic counseling LLMs (JGCLLMs) are underexplored. To advance a JGCLLM-based dialogue system for genetic counseling, effective domain adaptation methods require investigation.</p><p><strong>Objective: </strong>This study aims to evaluate the current capabilities and identify challenges in developing a JGCLLM-based dialogue system for genetic counseling. The primary focus is to assess the effectiveness of prompt engineering, retrieval-augmented generation (RAG), and instruction tuning within the context of genetic counseling. Furthermore, we will establish an experts-evaluated dataset of responses generated by LLMs adapted to Japanese genetic counseling for the future development of JGCLLMs.</p><p><strong>Methods: </strong>Two primary datasets were used in this study: (1) a question-answer (QA) dataset for LLM adaptation and (2) a genetic counseling question dataset for evaluation. The QA dataset included 899 QA pairs covering medical and genetic counseling topics, while the evaluation dataset contained 120 curated questions across 6 genetic counseling categories. Three enhancement techniques of LLMs-instruction tuning, RAG, and prompt engineering-were applied to a lightweight Japanese LLM to enhance its ability for genetic counseling. The performance of the adapted LLM was evaluated on the 120-question dataset by 2 certified genetic counselors and 1 ophthalmologist (SK, YU, and AY). Evaluation focused on four metrics: (1) inappropriateness of information, (2) sufficiency of information, (3) severity of harm, and (4) alignment with medical consensus.</p><p><strong>Results: </strong>The evaluation by certified genetic counselors and an ophthalmologist revealed varied outcomes across different methods. RAG showed potential, particularly in enhancing critical aspects of genetic counseling. In contrast, instruction tuning and prompt engineering produced less favorable outcomes. This evaluation process facilitated the creation an expert-evaluated dataset of responses generated by LLMs adapted with different combinations of these methods. Error analysis identified key ethical concerns, including inappropriate promotion of prenatal testing, criticism of relatives, and inaccurate probability statements.</p><p><strong>Conclusions: </strong>RAG demonstrated notable improvements across all evaluation metrics, suggesting potential for further enhancement through the expansion of RAG data. The expert-evaluated dataset developed in this study provides valuable insights for future optimization efforts. However, the ethical issues observed in JGCLLM responses underscore the critical need for ongoing refinement and thorough ethical evaluation before these systems can be implemented in health care settings.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e65047"},"PeriodicalIF":3.8000,"publicationDate":"2025-01-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11783024/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/65047","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Advances in genetics have underscored a strong association between genetic factors and health outcomes, leading to an increased demand for genetic counseling services. However, a shortage of qualified genetic counselors poses a significant challenge. Large language models (LLMs) have emerged as a potential solution for augmenting support in genetic counseling tasks. Despite the potential, Japanese genetic counseling LLMs (JGCLLMs) are underexplored. To advance a JGCLLM-based dialogue system for genetic counseling, effective domain adaptation methods require investigation.
Objective: This study aims to evaluate the current capabilities and identify challenges in developing a JGCLLM-based dialogue system for genetic counseling. The primary focus is to assess the effectiveness of prompt engineering, retrieval-augmented generation (RAG), and instruction tuning within the context of genetic counseling. Furthermore, we will establish an experts-evaluated dataset of responses generated by LLMs adapted to Japanese genetic counseling for the future development of JGCLLMs.
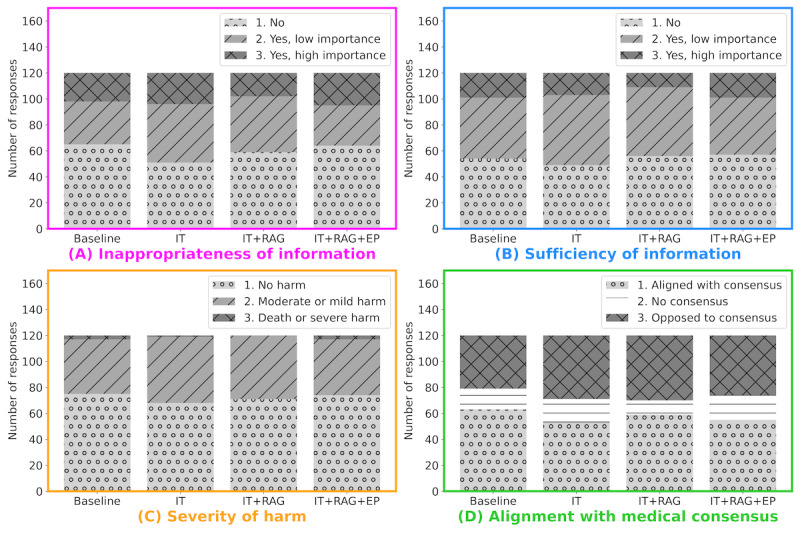
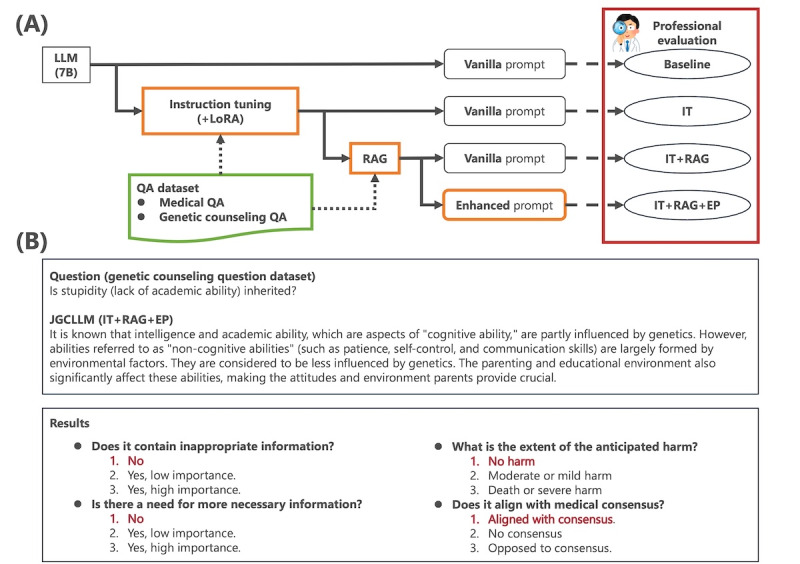
Methods: Two primary datasets were used in this study: (1) a question-answer (QA) dataset for LLM adaptation and (2) a genetic counseling question dataset for evaluation. The QA dataset included 899 QA pairs covering medical and genetic counseling topics, while the evaluation dataset contained 120 curated questions across 6 genetic counseling categories. Three enhancement techniques of LLMs-instruction tuning, RAG, and prompt engineering-were applied to a lightweight Japanese LLM to enhance its ability for genetic counseling. The performance of the adapted LLM was evaluated on the 120-question dataset by 2 certified genetic counselors and 1 ophthalmologist (SK, YU, and AY). Evaluation focused on four metrics: (1) inappropriateness of information, (2) sufficiency of information, (3) severity of harm, and (4) alignment with medical consensus.
Results: The evaluation by certified genetic counselors and an ophthalmologist revealed varied outcomes across different methods. RAG showed potential, particularly in enhancing critical aspects of genetic counseling. In contrast, instruction tuning and prompt engineering produced less favorable outcomes. This evaluation process facilitated the creation an expert-evaluated dataset of responses generated by LLMs adapted with different combinations of these methods. Error analysis identified key ethical concerns, including inappropriate promotion of prenatal testing, criticism of relatives, and inaccurate probability statements.
Conclusions: RAG demonstrated notable improvements across all evaluation metrics, suggesting potential for further enhancement through the expansion of RAG data. The expert-evaluated dataset developed in this study provides valuable insights for future optimization efforts. However, the ethical issues observed in JGCLLM responses underscore the critical need for ongoing refinement and thorough ethical evaluation before these systems can be implemented in health care settings.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
