Perseus V. Patel , Conner Davis , Amariel Ralbovsky , Daniel Tinoco , Christopher Y.K. Williams , Shadera Slatter , Behzad Naderalvojoud , Michael J. Rosen , Tina Hernandez-Boussard , Vivek Rudrapatna
{"title":"Large Language Models Outperform Traditional Natural Language Processing Methods in Extracting Patient-Reported Outcomes in Inflammatory Bowel Disease","authors":"Perseus V. Patel , Conner Davis , Amariel Ralbovsky , Daniel Tinoco , Christopher Y.K. Williams , Shadera Slatter , Behzad Naderalvojoud , Michael J. Rosen , Tina Hernandez-Boussard , Vivek Rudrapatna","doi":"10.1016/j.gastha.2024.10.003","DOIUrl":null,"url":null,"abstract":"<div><h3>Background and Aims</h3><div>Patient-reported outcomes (PROs) are vital in assessing disease activity and treatment outcomes in inflammatory bowel disease (IBD). However, manual extraction of these PROs from the free-text of clinical notes is burdensome. We aimed to improve data curation from free-text information in the electronic health record, making it more available for research and quality improvement. This study aimed to compare traditional natural language processing (tNLP) and large language models (LLMs) in extracting 3 IBD PROs (abdominal pain, diarrhea, fecal blood) from clinical notes across 2 institutions.</div></div><div><h3>Methods</h3><div>Clinic notes were annotated for each PRO using preset protocols. Models were developed and internally tested at the University of California, San Francisco, and then externally validated at Stanford University. We compared tNLP and LLM-based models on accuracy, sensitivity, specificity, positive, and negative predictive value. In addition, we conducted fairness and error assessments.</div></div><div><h3>Results</h3><div>Interrater reliability between annotators was >90%. On the University of California, San Francisco test set (n = 50), the top-performing tNLP models showcased accuracies of 92% (abdominal pain), 82% (diarrhea) and 80% (fecal blood), comparable to GPT-4, which was 96%, 88%, and 90% accurate, respectively. On external validation at Stanford (n = 250), tNLP models failed to generalize (61%–62% accuracy) while GPT-4 maintained accuracies >90%. Pathways Language Model-2 and Generative Pre-trained Transformer-4 showed similar performance. No biases were detected based on demographics or diagnosis.</div></div><div><h3>Conclusion</h3><div>LLMs are accurate and generalizable methods for extracting PROs. They maintain excellent accuracy across institutions, despite heterogeneity in note templates and authors. Widespread adoption of such tools has the potential to enhance IBD research and patient care.</div></div>","PeriodicalId":73130,"journal":{"name":"Gastro hep advances","volume":"4 2","pages":"Article 100563"},"PeriodicalIF":0.0000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11772946/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Gastro hep advances","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2772572324001584","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/10 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background and Aims
Patient-reported outcomes (PROs) are vital in assessing disease activity and treatment outcomes in inflammatory bowel disease (IBD). However, manual extraction of these PROs from the free-text of clinical notes is burdensome. We aimed to improve data curation from free-text information in the electronic health record, making it more available for research and quality improvement. This study aimed to compare traditional natural language processing (tNLP) and large language models (LLMs) in extracting 3 IBD PROs (abdominal pain, diarrhea, fecal blood) from clinical notes across 2 institutions.
Methods
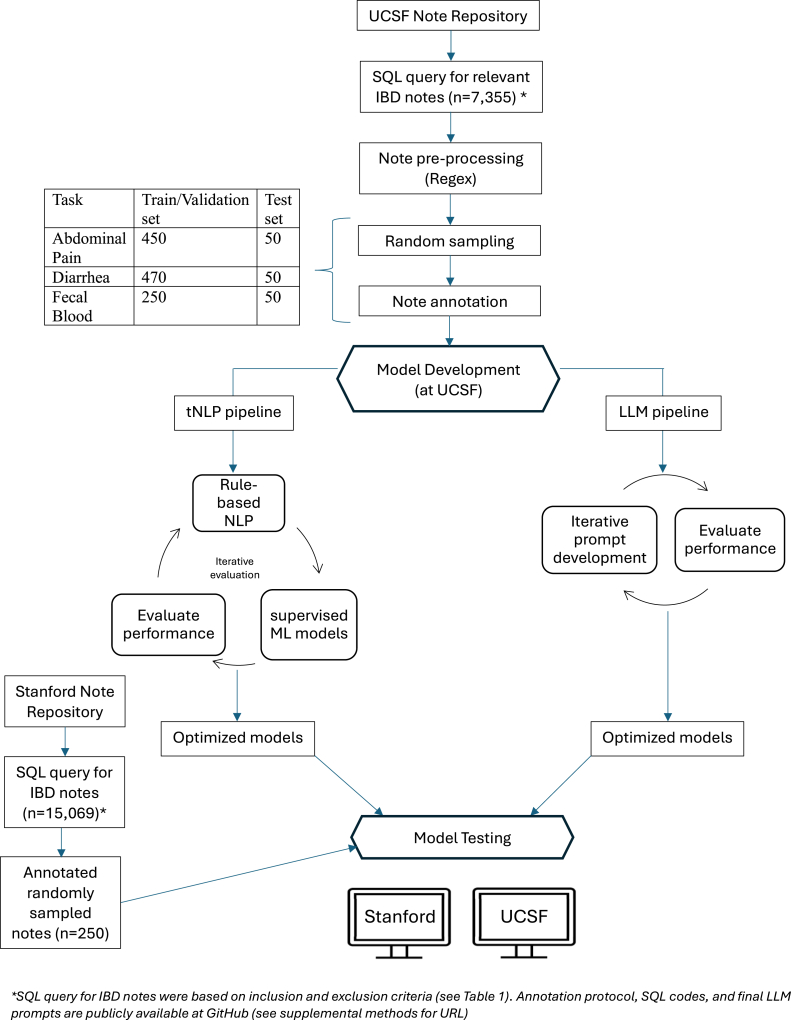
Clinic notes were annotated for each PRO using preset protocols. Models were developed and internally tested at the University of California, San Francisco, and then externally validated at Stanford University. We compared tNLP and LLM-based models on accuracy, sensitivity, specificity, positive, and negative predictive value. In addition, we conducted fairness and error assessments.
Results
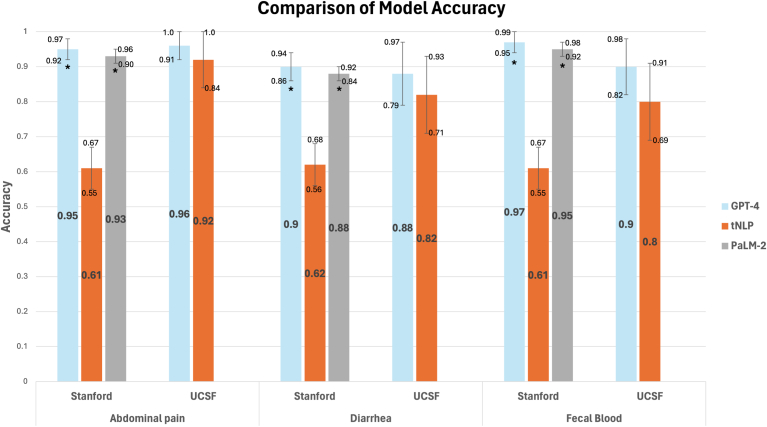
Interrater reliability between annotators was >90%. On the University of California, San Francisco test set (n = 50), the top-performing tNLP models showcased accuracies of 92% (abdominal pain), 82% (diarrhea) and 80% (fecal blood), comparable to GPT-4, which was 96%, 88%, and 90% accurate, respectively. On external validation at Stanford (n = 250), tNLP models failed to generalize (61%–62% accuracy) while GPT-4 maintained accuracies >90%. Pathways Language Model-2 and Generative Pre-trained Transformer-4 showed similar performance. No biases were detected based on demographics or diagnosis.
Conclusion
LLMs are accurate and generalizable methods for extracting PROs. They maintain excellent accuracy across institutions, despite heterogeneity in note templates and authors. Widespread adoption of such tools has the potential to enhance IBD research and patient care.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
