Melissa D McCradden, Kelly Thai, Azadeh Assadi, Sana Tonekaboni, Ian Stedman, Shalmali Joshi, Minfan Zhang, Fanny Chevalier, Anna Goldenberg
{"title":"What makes a 'good' decision with artificial intelligence? A grounded theory study in paediatric care.","authors":"Melissa D McCradden, Kelly Thai, Azadeh Assadi, Sana Tonekaboni, Ian Stedman, Shalmali Joshi, Minfan Zhang, Fanny Chevalier, Anna Goldenberg","doi":"10.1136/bmjebm-2024-112919","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>To develop a framework for good clinical decision-making using machine learning (ML) models for interventional, patient-level decisions.</p><p><strong>Design: </strong>Grounded theory qualitative interview study.</p><p><strong>Setting: </strong>Primarily single-site at a major urban academic paediatric hospital, with external sampling.</p><p><strong>Participants: </strong>Sixteen participants representing physicians (n=10), nursing (n=3), respiratory therapists (n=2) and an ML specialist (n=1) with experience working in acute care environments were identified through purposive sampling. Individuals were recruited to represent a spectrum of ML knowledge (three expert, four knowledgeable and nine non-expert) and years of experience (median=12.9 years postgraduation). Recruitment proceeded through snowball sampling, with individuals approached to represent a diversity of fields, levels of experience and attitudes towards artificial intelligence (AI)/ML. A member check step and consultation with patients was undertaken to vet the framework, which resulted in some minor revisions to the wording and framing.</p><p><strong>Interventions: </strong>A semi-structured virtual interview simulating an intensive care unit handover for a hypothetical patient case using a simulated ML model and seven visualisations using known methods addressing interpretability of models in healthcare. Participants were asked to make an initial care plan for the patient, then were presented with a model prediction followed by the seven visualisations to explore their judgement and potential influence and understanding of the visualisations. Two visualisations contained contradicting information to probe participants' resolution process for the contrasting information. The ethical justifiability and clinical reasoning process were explored.</p><p><strong>Main outcome: </strong>A comprehensive framework was developed that is grounded in established medicolegal and ethical standards and accounts for the incorporation of inference from ML models.</p><p><strong>Results: </strong>We found that for making good decisions, participants reflected across six main categories: evidence, facts and medical knowledge relevant to the patient's condition; how that knowledge may be applied to this particular patient; patient-level, family-specific and local factors; facts about the model, its development and testing; the patient-level knowledge sufficiently represented by the model; the model's incorporation of relevant contextual factors. This judgement was centred on and anchored most heavily on the overall balance of benefits and risks to the patient, framed by the goals of care. We found evidence of automation bias, with many participants assuming that if the model's explanation conflicted with their prior knowledge that their judgement was incorrect; others concluded the exact opposite, drawing from their medical knowledge base to reject the incorrect information provided in the explanation. Regarding knowledge about the model, we found that participants most consistently wanted to know about the model's historical performance in the cohort of patients in their local unit where the hypothetical patient was situated.</p><p><strong>Conclusion: </strong>Good decisions using AI tools require reflection across multiple domains. We provide an actionable framework and question guide to support clinical decision-making with AI.</p>","PeriodicalId":9059,"journal":{"name":"BMJ Evidence-Based Medicine","volume":" ","pages":"183-193"},"PeriodicalIF":7.6000,"publicationDate":"2025-05-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12171473/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Evidence-Based Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1136/bmjebm-2024-112919","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MEDICINE, GENERAL & INTERNAL","Score":null,"Total":0}
引用次数: 0
Abstract
Objective: To develop a framework for good clinical decision-making using machine learning (ML) models for interventional, patient-level decisions.
Design: Grounded theory qualitative interview study.
Setting: Primarily single-site at a major urban academic paediatric hospital, with external sampling.
Participants: Sixteen participants representing physicians (n=10), nursing (n=3), respiratory therapists (n=2) and an ML specialist (n=1) with experience working in acute care environments were identified through purposive sampling. Individuals were recruited to represent a spectrum of ML knowledge (three expert, four knowledgeable and nine non-expert) and years of experience (median=12.9 years postgraduation). Recruitment proceeded through snowball sampling, with individuals approached to represent a diversity of fields, levels of experience and attitudes towards artificial intelligence (AI)/ML. A member check step and consultation with patients was undertaken to vet the framework, which resulted in some minor revisions to the wording and framing.
Interventions: A semi-structured virtual interview simulating an intensive care unit handover for a hypothetical patient case using a simulated ML model and seven visualisations using known methods addressing interpretability of models in healthcare. Participants were asked to make an initial care plan for the patient, then were presented with a model prediction followed by the seven visualisations to explore their judgement and potential influence and understanding of the visualisations. Two visualisations contained contradicting information to probe participants' resolution process for the contrasting information. The ethical justifiability and clinical reasoning process were explored.
Main outcome: A comprehensive framework was developed that is grounded in established medicolegal and ethical standards and accounts for the incorporation of inference from ML models.
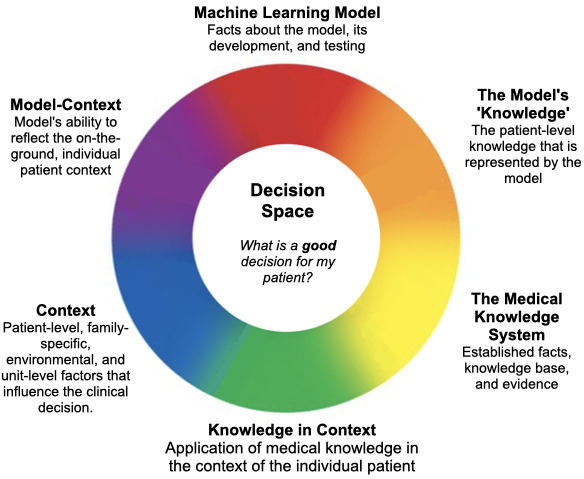
Results: We found that for making good decisions, participants reflected across six main categories: evidence, facts and medical knowledge relevant to the patient's condition; how that knowledge may be applied to this particular patient; patient-level, family-specific and local factors; facts about the model, its development and testing; the patient-level knowledge sufficiently represented by the model; the model's incorporation of relevant contextual factors. This judgement was centred on and anchored most heavily on the overall balance of benefits and risks to the patient, framed by the goals of care. We found evidence of automation bias, with many participants assuming that if the model's explanation conflicted with their prior knowledge that their judgement was incorrect; others concluded the exact opposite, drawing from their medical knowledge base to reject the incorrect information provided in the explanation. Regarding knowledge about the model, we found that participants most consistently wanted to know about the model's historical performance in the cohort of patients in their local unit where the hypothetical patient was situated.
Conclusion: Good decisions using AI tools require reflection across multiple domains. We provide an actionable framework and question guide to support clinical decision-making with AI.
期刊介绍:
BMJ Evidence-Based Medicine (BMJ EBM) publishes original evidence-based research, insights and opinions on what matters for health care. We focus on the tools, methods, and concepts that are basic and central to practising evidence-based medicine and deliver relevant, trustworthy and impactful evidence.
BMJ EBM is a Plan S compliant Transformative Journal and adheres to the highest possible industry standards for editorial policies and publication ethics.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
