{"title":"Identifying COVID-19-Infected Segments in Lung CT Scan Through Two Innovative Artificial Intelligence-Based Transformer Models.","authors":"Zeinab Momeni Pour, Ali Asghar Beheshti Shirazi","doi":"10.22037/aaemj.v13i1.2515","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Automatic systems based on Artificial intelligence (AI) algorithms have made significant advancements across various domains, most notably in the field of medicine. This study introduces a novel approach for identifying COVID-19-infected regions in lung computed tomography (CT) scan through the development of two innovative models.</p><p><strong>Methods: </strong>In this study we used the Squeeze and Excitation based UNet TRansformers (SE-UNETR) and the Squeeze and Excitation based High-Quality Resolution Swin Transformer Network (SE-HQRSTNet), to develop two three-dimensional segmentation networks for identifying COVID-19-infected regions in lung CT scan. The SE-UNETR model is structured as a 3D UNet architecture with an encoder component built on Vision Transformers (ViTs). This model processes 3D patches directly as input and learns sequential representations of the volumetric data. The encoder connects to the decoder using skip connections, ultimately producing the final semantic segmentation output. Conversely, the SE-HQRSTNet model incorporates High-Resolution Networks (HRNet), Swin Transformer modules, and Squeeze and Excitation (SE) blocks. This architecture is designed to generate features at multiple resolutions, utilizing Multi-Resolution Feature Fusion (MRFF) blocks to effectively integrate semantic features across various scales. The proposed networks were evaluated using a 5-fold cross-validation methodology, along with data augmentation techniques, applied to the COVID-19-CT-Seg and MosMed datasets.</p><p><strong>Results: </strong>experimental results demonstrate that the Dice value for the infection masks within the COVID-19-CT-Seg dataset improved by 3.81% and 4.84% with the SE-UNETR and SE-HQRSTNet models, respectively, compared to previously reported work. Furthermore, the Dice value for the MosMed dataset increased from 66.8% to 69.35% and 70.89% for the SE-UNETR and SE-HQRSTNet models, respectively.</p><p><strong>Conclusion: </strong>These improvements indicate that the proposed models exhibit superior efficiency and performance relative to existing methodologies.</p>","PeriodicalId":8146,"journal":{"name":"Archives of Academic Emergency Medicine","volume":"13 1","pages":"e21"},"PeriodicalIF":2.0000,"publicationDate":"2024-12-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11829223/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Archives of Academic Emergency Medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.22037/aaemj.v13i1.2515","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"EMERGENCY MEDICINE","Score":null,"Total":0}
引用次数: 0
Abstract
Introduction: Automatic systems based on Artificial intelligence (AI) algorithms have made significant advancements across various domains, most notably in the field of medicine. This study introduces a novel approach for identifying COVID-19-infected regions in lung computed tomography (CT) scan through the development of two innovative models.
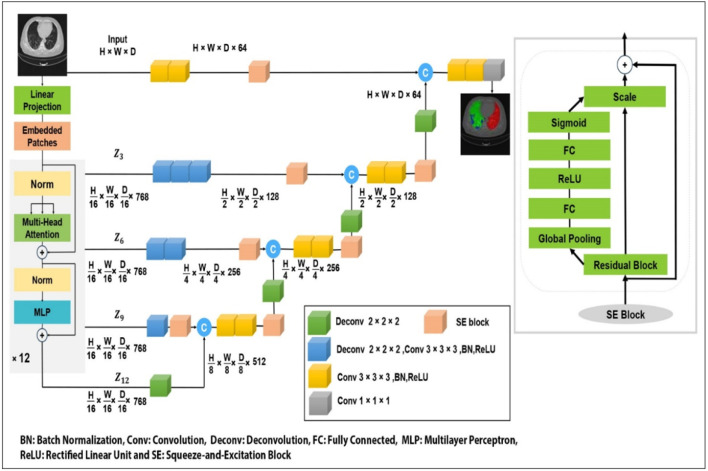
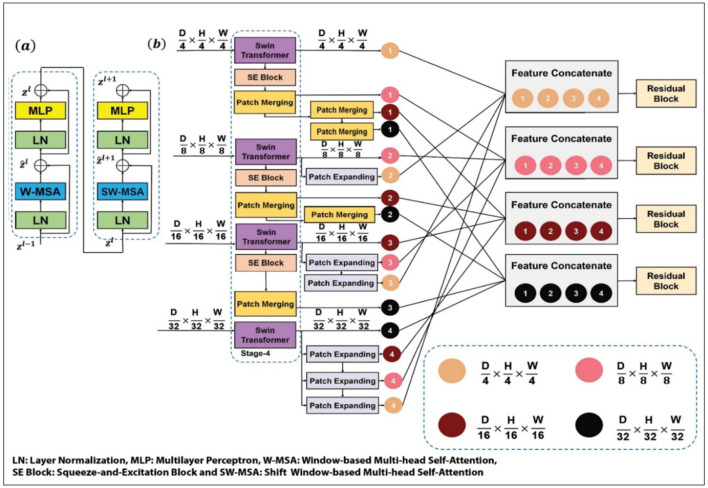
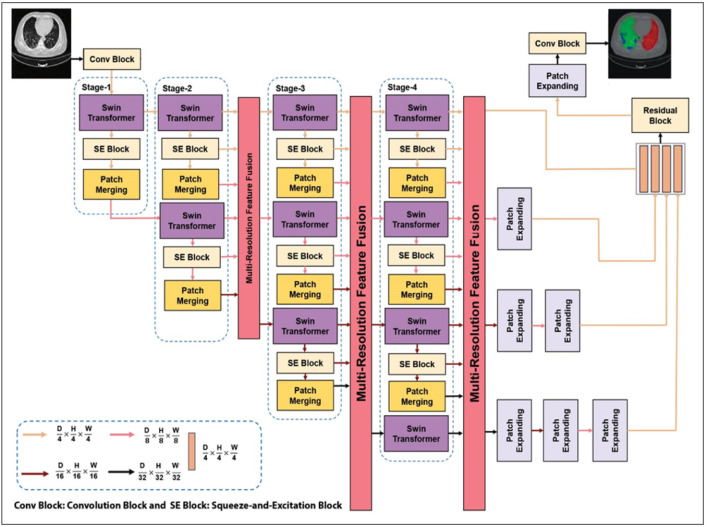
Methods: In this study we used the Squeeze and Excitation based UNet TRansformers (SE-UNETR) and the Squeeze and Excitation based High-Quality Resolution Swin Transformer Network (SE-HQRSTNet), to develop two three-dimensional segmentation networks for identifying COVID-19-infected regions in lung CT scan. The SE-UNETR model is structured as a 3D UNet architecture with an encoder component built on Vision Transformers (ViTs). This model processes 3D patches directly as input and learns sequential representations of the volumetric data. The encoder connects to the decoder using skip connections, ultimately producing the final semantic segmentation output. Conversely, the SE-HQRSTNet model incorporates High-Resolution Networks (HRNet), Swin Transformer modules, and Squeeze and Excitation (SE) blocks. This architecture is designed to generate features at multiple resolutions, utilizing Multi-Resolution Feature Fusion (MRFF) blocks to effectively integrate semantic features across various scales. The proposed networks were evaluated using a 5-fold cross-validation methodology, along with data augmentation techniques, applied to the COVID-19-CT-Seg and MosMed datasets.
Results: experimental results demonstrate that the Dice value for the infection masks within the COVID-19-CT-Seg dataset improved by 3.81% and 4.84% with the SE-UNETR and SE-HQRSTNet models, respectively, compared to previously reported work. Furthermore, the Dice value for the MosMed dataset increased from 66.8% to 69.35% and 70.89% for the SE-UNETR and SE-HQRSTNet models, respectively.
Conclusion: These improvements indicate that the proposed models exhibit superior efficiency and performance relative to existing methodologies.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
