Fattah H Fattah, Abdulwahid M Salih, Ameer M Salih, Saywan K Asaad, Abdullah K Ghafour, Rawa Bapir, Berun A Abdalla, Snur Othman, Sasan M Ahmed, Sabah Jalal Hasan, Yousif M Mahmood, Fahmi H Kakamad
{"title":"Comparative analysis of ChatGPT and Gemini (Bard) in medical inquiry: a scoping review.","authors":"Fattah H Fattah, Abdulwahid M Salih, Ameer M Salih, Saywan K Asaad, Abdullah K Ghafour, Rawa Bapir, Berun A Abdalla, Snur Othman, Sasan M Ahmed, Sabah Jalal Hasan, Yousif M Mahmood, Fahmi H Kakamad","doi":"10.3389/fdgth.2025.1482712","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Artificial intelligence and machine learning are popular interconnected technologies. AI chatbots like ChatGPT and Gemini show considerable promise in medical inquiries. This scoping review aims to assess the accuracy and response length (in characters) of ChatGPT and Gemini in medical applications.</p><p><strong>Methods: </strong>The eligible databases were searched to find studies published in English from January 1 to October 20, 2023. The inclusion criteria consisted of studies that focused on using AI in medicine and assessed outcomes based on the accuracy and character count (length) of ChatGPT and Gemini. Data collected from the studies included the first author's name, the country where the study was conducted, the type of study design, publication year, sample size, medical speciality, and the accuracy and response length.</p><p><strong>Results: </strong>The initial search identified 64 papers, with 11 meeting the inclusion criteria, involving 1,177 samples. ChatGPT showed higher accuracy in radiology (87.43% vs. Gemini's 71%) and shorter responses (907 vs. 1,428 characters). Similar trends were noted in other specialties. However, Gemini outperformed ChatGPT in emergency scenarios (87% vs. 77%) and in renal diets with low potassium and high phosphorus (79% vs. 60% and 100% vs. 77%). Statistical analysis confirms that ChatGPT has greater accuracy and shorter responses than Gemini in medical studies, with a <i>p</i>-value of <.001 for both metrics.</p><p><strong>Conclusion: </strong>This Scoping review suggests that ChatGPT may demonstrate higher accuracy and provide shorter responses than Gemini in medical studies.</p>","PeriodicalId":73078,"journal":{"name":"Frontiers in digital health","volume":"7 ","pages":"1482712"},"PeriodicalIF":3.2000,"publicationDate":"2025-02-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11830737/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fdgth.2025.1482712","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Introduction: Artificial intelligence and machine learning are popular interconnected technologies. AI chatbots like ChatGPT and Gemini show considerable promise in medical inquiries. This scoping review aims to assess the accuracy and response length (in characters) of ChatGPT and Gemini in medical applications.
Methods: The eligible databases were searched to find studies published in English from January 1 to October 20, 2023. The inclusion criteria consisted of studies that focused on using AI in medicine and assessed outcomes based on the accuracy and character count (length) of ChatGPT and Gemini. Data collected from the studies included the first author's name, the country where the study was conducted, the type of study design, publication year, sample size, medical speciality, and the accuracy and response length.
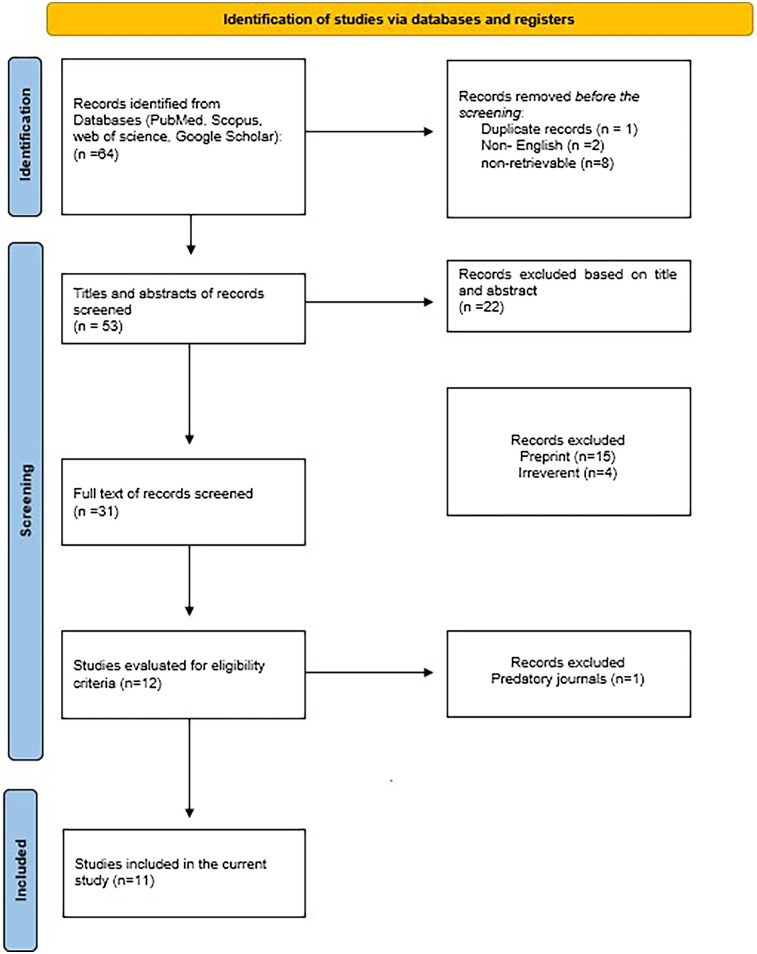
Results: The initial search identified 64 papers, with 11 meeting the inclusion criteria, involving 1,177 samples. ChatGPT showed higher accuracy in radiology (87.43% vs. Gemini's 71%) and shorter responses (907 vs. 1,428 characters). Similar trends were noted in other specialties. However, Gemini outperformed ChatGPT in emergency scenarios (87% vs. 77%) and in renal diets with low potassium and high phosphorus (79% vs. 60% and 100% vs. 77%). Statistical analysis confirms that ChatGPT has greater accuracy and shorter responses than Gemini in medical studies, with a p-value of <.001 for both metrics.
Conclusion: This Scoping review suggests that ChatGPT may demonstrate higher accuracy and provide shorter responses than Gemini in medical studies.
人工智能和机器学习是流行的互联技术。ChatGPT和Gemini等人工智能聊天机器人在医疗咨询方面显示出相当大的前景。本综述旨在评估ChatGPT和Gemini在医学应用中的准确性和响应长度(以字符为单位)。方法:检索符合条件的数据库,检索2023年1月1日至10月20日发表的英文文献。纳入标准包括专注于在医学中使用人工智能的研究,并根据ChatGPT和Gemini的准确性和字符数(长度)评估结果。从研究中收集的数据包括第一作者的姓名、研究进行的国家、研究设计的类型、出版年份、样本量、医学专业、准确性和反应长度。结果:初步检索到64篇论文,符合纳入标准的有11篇,涉及样本1177个。ChatGPT在放射学方面显示出更高的准确性(87.43% vs. Gemini的71%)和更短的反应(907 vs. 1428个字符)。其他专业也出现了类似的趋势。然而,Gemini在紧急情况下(87%对77%)和低钾高磷肾饮食(79%对60%和100%对77%)的表现优于ChatGPT。统计分析证实,ChatGPT在医学研究中比Gemini具有更高的准确性和更短的反应时间,p值为。结论:本Scoping综述表明,ChatGPT在医学研究中可能比Gemini具有更高的准确性和更短的反应时间。


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
