Validating large language models against manual information extraction from case reports of drug-induced parkinsonism in patients with schizophrenia spectrum and mood disorders: a proof of concept study.
Sebastian Volkmer, Alina Glück, Andreas Meyer-Lindenberg, Emanuel Schwarz, Dusan Hirjak
{"title":"Validating large language models against manual information extraction from case reports of drug-induced parkinsonism in patients with schizophrenia spectrum and mood disorders: a proof of concept study.","authors":"Sebastian Volkmer, Alina Glück, Andreas Meyer-Lindenberg, Emanuel Schwarz, Dusan Hirjak","doi":"10.1038/s41537-025-00601-5","DOIUrl":null,"url":null,"abstract":"<p><p>In this proof of concept study, we demonstrated how Large Language Models (LLMs) can automate the conversion of unstructured case reports into clinical ratings. By leveraging instructions from a standardized clinical rating scale and evaluating the LLM's confidence in its outputs, we aimed to refine prompting strategies and enhance reproducibility. Using this strategy and case reports of drug-induced Parkinsonism, we showed that LLM-extracted data closely align with clinical rater manual extraction, achieving an accuracy of 90%.</p>","PeriodicalId":74758,"journal":{"name":"Schizophrenia (Heidelberg, Germany)","volume":"11 1","pages":"47"},"PeriodicalIF":4.1000,"publicationDate":"2025-03-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11926372/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Schizophrenia (Heidelberg, Germany)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1038/s41537-025-00601-5","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PSYCHIATRY","Score":null,"Total":0}
引用次数: 0
Abstract
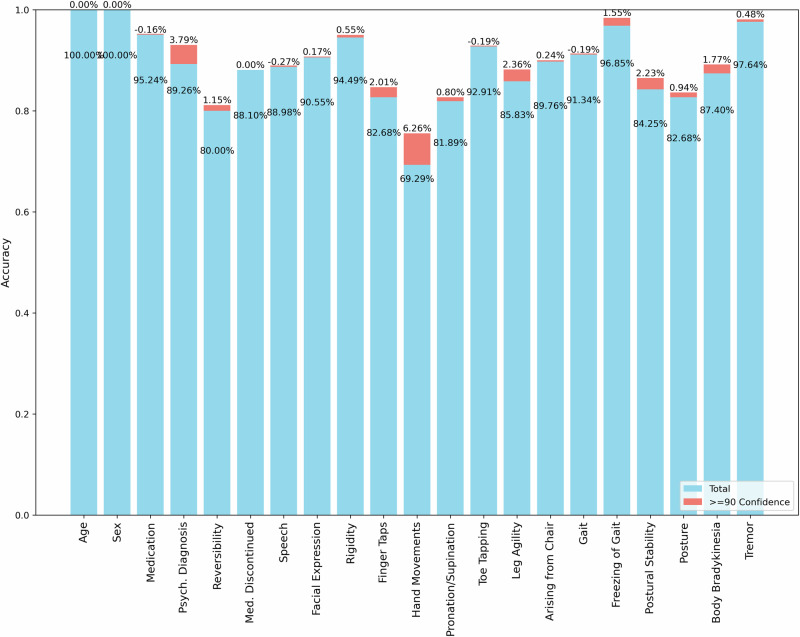
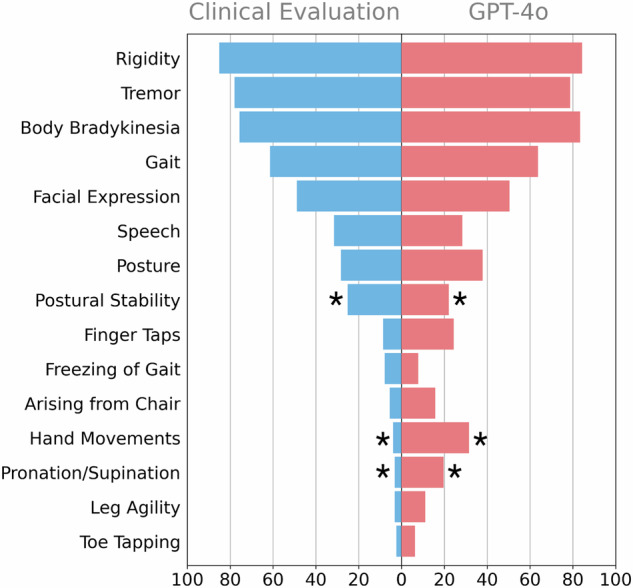
In this proof of concept study, we demonstrated how Large Language Models (LLMs) can automate the conversion of unstructured case reports into clinical ratings. By leveraging instructions from a standardized clinical rating scale and evaluating the LLM's confidence in its outputs, we aimed to refine prompting strategies and enhance reproducibility. Using this strategy and case reports of drug-induced Parkinsonism, we showed that LLM-extracted data closely align with clinical rater manual extraction, achieving an accuracy of 90%.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
