Leo Uramoto, Yuichiro Hayashi, Masahiro Oda, Takayuki Kitasaka, Kensaku Mori
{"title":"Semantic segmentation dataset authoring with simplified labels.","authors":"Leo Uramoto, Yuichiro Hayashi, Masahiro Oda, Takayuki Kitasaka, Kensaku Mori","doi":"10.1007/s11548-024-03314-9","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>Semantic segmentation of laparoscopic images is a key problem in surgical scene understanding. Creating ground truth labels for semantic segmentation tasks is time consuming, and in the medical field a need for medical training of annotators adds further complications, leading to reliance on a small pool of experts. Previous research has focused on reducing the time to author datasets, by using spatially weak labels, pseudolabels, and synthetic data. In this paper, we address the difficulties caused by the need for medically trained annotators, hoping to enable non-medical annotators to participate in medical annotation tasks, to ease the creation of large datasets.</p><p><strong>Methods: </strong>We propose simplified labels, labels that are semantically weak. Our labels allow non-medical annotators to participate in medical dataset authoring, by lowering the need for medical expertise. We simulate authoring processes with mixtures of medical and non-medical annotators and measure the impact adding non-medical annotators has on accuracy. We also show that simplified labels offer a simple formulation for multi-dataset training.</p><p><strong>Results: </strong>We show that simplified labels are a viable approach to dataset authoring. Including non-medical annotators in the authoring process is beneficial, but medically trained annotators are worth multiple non-medical annotators, with maximal Dice score increases of 9.3% for 1 medically trained annotator and 6.9% for 3 non-medical annotators. We also show that the labels offer a simple formulation for multi-dataset training, even with no overlapping classes. We find that converting the labels of a secondary incompatible dataset into simplified labels and jointly training on both datasets improves performance.</p><p><strong>Conclusion: </strong>Simplified labels offer a framework that can be applied both to dataset authoring and to multi-dataset training. Using the proposed method, non-medical annotators can participate in semantic segmentation dataset authoring. Labels of incompatible datasets can be converted into simplified datasets, enabling multi-dataset training.</p>","PeriodicalId":51251,"journal":{"name":"International Journal of Computer Assisted Radiology and Surgery","volume":" ","pages":"1003-1013"},"PeriodicalIF":2.3000,"publicationDate":"2025-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12055892/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Computer Assisted Radiology and Surgery","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1007/s11548-024-03314-9","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/4/5 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"ENGINEERING, BIOMEDICAL","Score":null,"Total":0}
引用次数: 0
Abstract
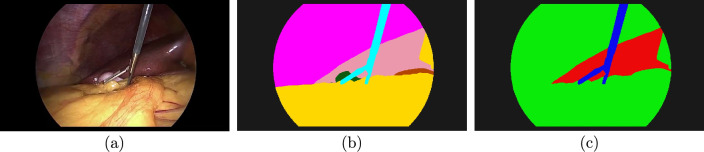
Purpose: Semantic segmentation of laparoscopic images is a key problem in surgical scene understanding. Creating ground truth labels for semantic segmentation tasks is time consuming, and in the medical field a need for medical training of annotators adds further complications, leading to reliance on a small pool of experts. Previous research has focused on reducing the time to author datasets, by using spatially weak labels, pseudolabels, and synthetic data. In this paper, we address the difficulties caused by the need for medically trained annotators, hoping to enable non-medical annotators to participate in medical annotation tasks, to ease the creation of large datasets.
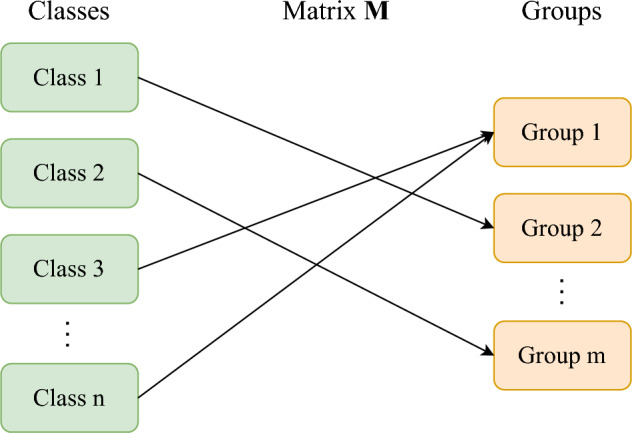
Methods: We propose simplified labels, labels that are semantically weak. Our labels allow non-medical annotators to participate in medical dataset authoring, by lowering the need for medical expertise. We simulate authoring processes with mixtures of medical and non-medical annotators and measure the impact adding non-medical annotators has on accuracy. We also show that simplified labels offer a simple formulation for multi-dataset training.
Results: We show that simplified labels are a viable approach to dataset authoring. Including non-medical annotators in the authoring process is beneficial, but medically trained annotators are worth multiple non-medical annotators, with maximal Dice score increases of 9.3% for 1 medically trained annotator and 6.9% for 3 non-medical annotators. We also show that the labels offer a simple formulation for multi-dataset training, even with no overlapping classes. We find that converting the labels of a secondary incompatible dataset into simplified labels and jointly training on both datasets improves performance.
Conclusion: Simplified labels offer a framework that can be applied both to dataset authoring and to multi-dataset training. Using the proposed method, non-medical annotators can participate in semantic segmentation dataset authoring. Labels of incompatible datasets can be converted into simplified datasets, enabling multi-dataset training.
期刊介绍:
The International Journal for Computer Assisted Radiology and Surgery (IJCARS) is a peer-reviewed journal that provides a platform for closing the gap between medical and technical disciplines, and encourages interdisciplinary research and development activities in an international environment.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
