Rajat Hebbar, Pavlos Papadopoulos, Ramon Reyes, Alexander F Danvers, Angelina J Polsinelli, Suzanne A Moseley, David A Sbarra, Matthias R Mehl, Shrikanth Narayanan
{"title":"Deep multiple instance learning for foreground speech localization in ambient audio from wearable devices.","authors":"Rajat Hebbar, Pavlos Papadopoulos, Ramon Reyes, Alexander F Danvers, Angelina J Polsinelli, Suzanne A Moseley, David A Sbarra, Matthias R Mehl, Shrikanth Narayanan","doi":"10.1186/s13636-020-00194-0","DOIUrl":null,"url":null,"abstract":"<p><p>Over the recent years, machine learning techniques have been employed to produce state-of-the-art results in several audio related tasks. The success of these approaches has been largely due to access to large amounts of open-source datasets and enhancement of computational resources. However, a shortcoming of these methods is that they often fail to generalize well to tasks from real life scenarios, due to domain mismatch. One such task is foreground speech detection from wearable audio devices. Several interfering factors such as dynamically varying environmental conditions, including background speakers, TV, or radio audio, render foreground speech detection to be a challenging task. Moreover, obtaining precise moment-to-moment annotations of audio streams for analysis and model training is also time-consuming and costly. In this work, we use multiple instance learning (MIL) to facilitate development of such models using annotations available at a lower time-resolution (coarsely labeled). We show how MIL can be applied to localize foreground speech in coarsely labeled audio and show both bag-level and instance-level results. We also study different pooling methods and how they can be adapted to densely distributed events as observed in our application. Finally, we show improvements using speech activity detection embeddings as features for foreground detection.</p>","PeriodicalId":49202,"journal":{"name":"Eurasip Journal on Audio Speech and Music Processing","volume":"2021 1","pages":"7"},"PeriodicalIF":1.9000,"publicationDate":"2021-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/s13636-020-00194-0","citationCount":"9","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Eurasip Journal on Audio Speech and Music Processing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s13636-020-00194-0","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/2/3 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"ACOUSTICS","Score":null,"Total":0}
引用次数: 9
Abstract
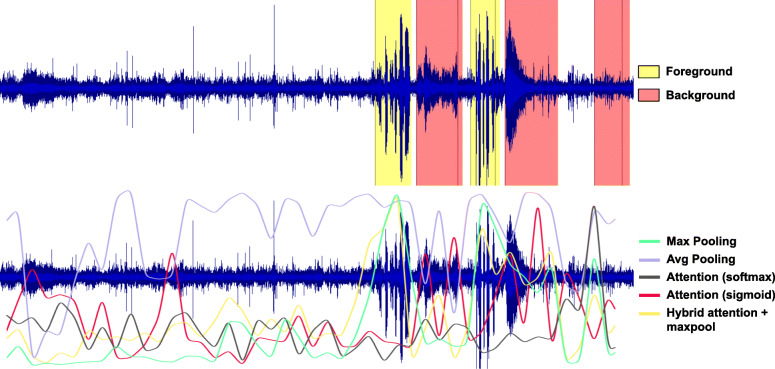
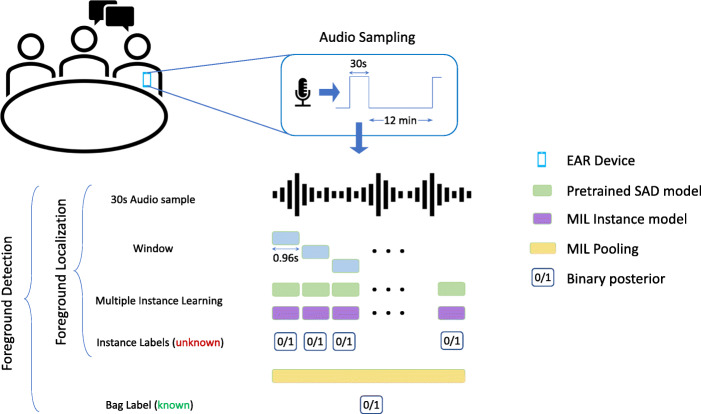
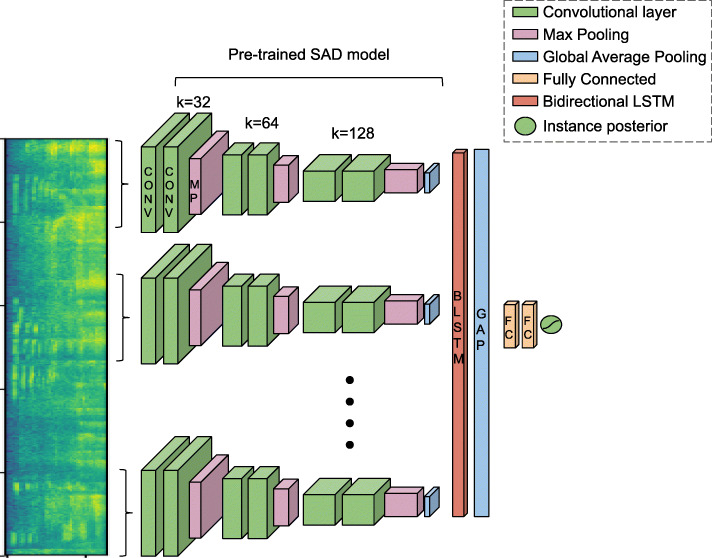
Over the recent years, machine learning techniques have been employed to produce state-of-the-art results in several audio related tasks. The success of these approaches has been largely due to access to large amounts of open-source datasets and enhancement of computational resources. However, a shortcoming of these methods is that they often fail to generalize well to tasks from real life scenarios, due to domain mismatch. One such task is foreground speech detection from wearable audio devices. Several interfering factors such as dynamically varying environmental conditions, including background speakers, TV, or radio audio, render foreground speech detection to be a challenging task. Moreover, obtaining precise moment-to-moment annotations of audio streams for analysis and model training is also time-consuming and costly. In this work, we use multiple instance learning (MIL) to facilitate development of such models using annotations available at a lower time-resolution (coarsely labeled). We show how MIL can be applied to localize foreground speech in coarsely labeled audio and show both bag-level and instance-level results. We also study different pooling methods and how they can be adapted to densely distributed events as observed in our application. Finally, we show improvements using speech activity detection embeddings as features for foreground detection.
期刊介绍:
The aim of “EURASIP Journal on Audio, Speech, and Music Processing” is to bring together researchers, scientists and engineers working on the theory and applications of the processing of various audio signals, with a specific focus on speech and music. EURASIP Journal on Audio, Speech, and Music Processing will be an interdisciplinary journal for the dissemination of all basic and applied aspects of speech communication and audio processes.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
