Grace L Smith, Ya-Chen T Shih, Sharon H Giordano, Benjamin D Smith, Thomas A Buchholz
{"title":"A method to predict breast cancer stage using Medicare claims.","authors":"Grace L Smith, Ya-Chen T Shih, Sharon H Giordano, Benjamin D Smith, Thomas A Buchholz","doi":"10.1186/1742-5573-7-1","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>In epidemiologic studies, cancer stage is an important predictor of outcomes. However, cancer stage is typically unavailable in medical insurance claims datasets, thus limiting the usefulness of such data for epidemiologic studies. Therefore, we sought to develop an algorithm to predict cancer stage based on covariates available from claims-based data.</p><p><strong>Methods: </strong>We identified a cohort of 77,306 women age >/= 66 years with stage I-IV breast cancer, using the Surveillence Epidemiology and End Results (SEER)-Medicare database. We formulated an algorithm to predict cancer stage using covariates (demographic, tumor, and treatment characteristics) obtained from claims. Logistic regression models derived prediction equations in a training set, and equations' test characteristics (sensitivity, specificity, positive predictive value (PPV), and negative predictive value [NPV]) were calculated in a validation set.</p><p><strong>Results: </strong>Of the entire sample of women diagnosed with invasive breast cancer, 51% had stage I; 26% stage II; 11% stage III; and 4% stage IV disease. The equation predicting stage IV disease achieved sensitivity of 81%, specificity 89%, positive predictive value (PPV) 24%, and negative predictive value (NPV) 99%, while the equation distinguishing stage I/II from stage III disease achieved sensitivity 83%, specificity 78%, PPV 98%, and NPV 31%. Combined, the equations most accurately identified early stage disease and ascertained a sample in which 98% of patients were stage I or II.</p><p><strong>Conclusions: </strong>A claims-based algorithm was utilized to predict breast cancer stage, and was particularly successful when used to identify early stage disease. These prediction equations may be applied in future studies of breast cancer patients, substantially improving the utility of claims-based studies in this group. This method may similarly be employed to develop algorithms permitting claims-based epidemiologic studies of patients with other cancers.</p>","PeriodicalId":87082,"journal":{"name":"Epidemiologic perspectives & innovations : EP+I","volume":"7 ","pages":"1"},"PeriodicalIF":0.0000,"publicationDate":"2010-01-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/1742-5573-7-1","citationCount":"38","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Epidemiologic perspectives & innovations : EP+I","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/1742-5573-7-1","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 38
Abstract
Background: In epidemiologic studies, cancer stage is an important predictor of outcomes. However, cancer stage is typically unavailable in medical insurance claims datasets, thus limiting the usefulness of such data for epidemiologic studies. Therefore, we sought to develop an algorithm to predict cancer stage based on covariates available from claims-based data.
Methods: We identified a cohort of 77,306 women age >/= 66 years with stage I-IV breast cancer, using the Surveillence Epidemiology and End Results (SEER)-Medicare database. We formulated an algorithm to predict cancer stage using covariates (demographic, tumor, and treatment characteristics) obtained from claims. Logistic regression models derived prediction equations in a training set, and equations' test characteristics (sensitivity, specificity, positive predictive value (PPV), and negative predictive value [NPV]) were calculated in a validation set.
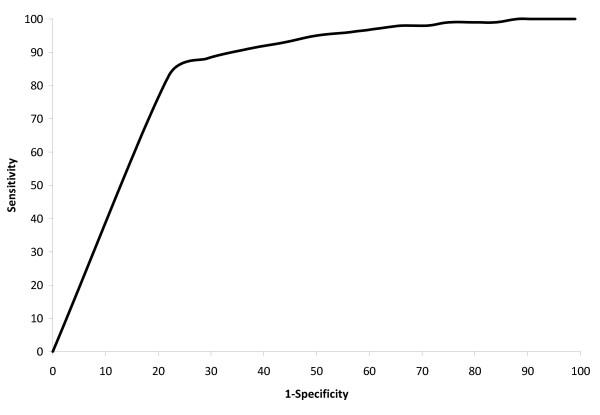
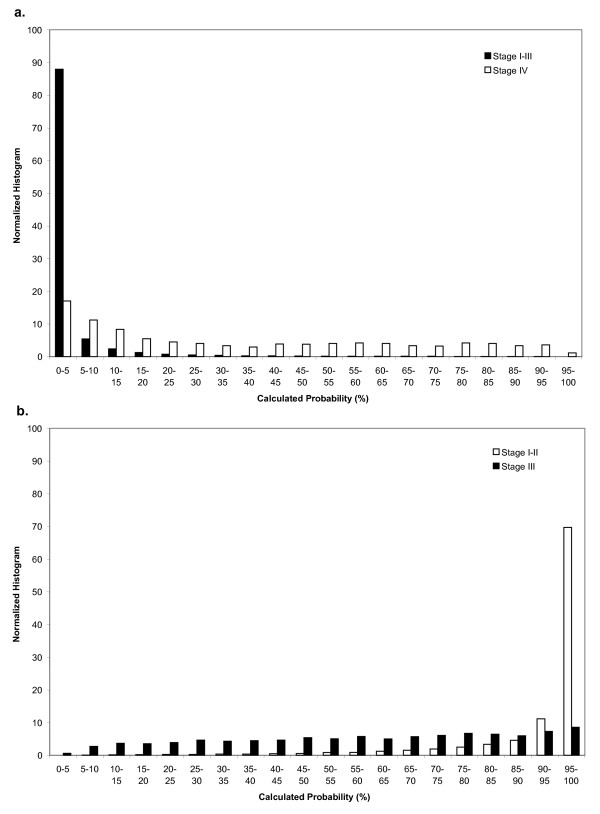
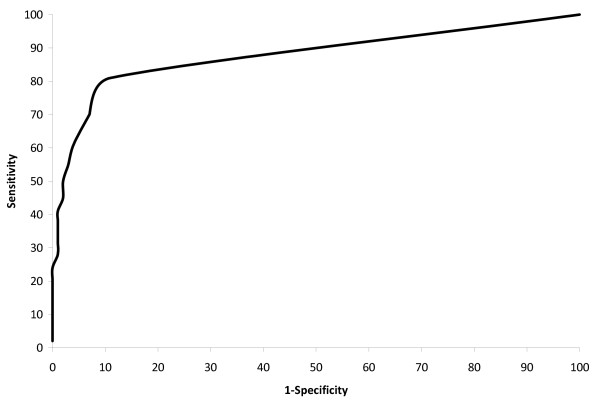
Results: Of the entire sample of women diagnosed with invasive breast cancer, 51% had stage I; 26% stage II; 11% stage III; and 4% stage IV disease. The equation predicting stage IV disease achieved sensitivity of 81%, specificity 89%, positive predictive value (PPV) 24%, and negative predictive value (NPV) 99%, while the equation distinguishing stage I/II from stage III disease achieved sensitivity 83%, specificity 78%, PPV 98%, and NPV 31%. Combined, the equations most accurately identified early stage disease and ascertained a sample in which 98% of patients were stage I or II.
Conclusions: A claims-based algorithm was utilized to predict breast cancer stage, and was particularly successful when used to identify early stage disease. These prediction equations may be applied in future studies of breast cancer patients, substantially improving the utility of claims-based studies in this group. This method may similarly be employed to develop algorithms permitting claims-based epidemiologic studies of patients with other cancers.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
