Characterization of uncertainty in the classification of multivariate assays: application to PAM50 centroid-based genomic predictors for breast cancer treatment plans.
Mark Tw Ebbert, Roy Rl Bastien, Kenneth M Boucher, Miguel Martín, Eva Carrasco, Rosalía Caballero, Inge J Stijleman, Philip S Bernard, Julio C Facelli
{"title":"Characterization of uncertainty in the classification of multivariate assays: application to PAM50 centroid-based genomic predictors for breast cancer treatment plans.","authors":"Mark Tw Ebbert, Roy Rl Bastien, Kenneth M Boucher, Miguel Martín, Eva Carrasco, Rosalía Caballero, Inge J Stijleman, Philip S Bernard, Julio C Facelli","doi":"10.1186/2043-9113-1-37","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Multivariate assays (MVAs) for assisting clinical decisions are becoming commonly available, but due to complexity, are often considered a high-risk approach. A key concern is that uncertainty on the assay's final results is not well understood. This study focuses on developing a process to characterize error introduced in the MVA's results from the intrinsic error in the laboratory process: sample preparation and measurement of the contributing factors, such as gene expression.</p><p><strong>Methods: </strong>Using the PAM50 Breast Cancer Intrinsic Classifier, we show how to characterize error within an MVA, and how these errors may affect results reported to clinicians. First we estimated the error distribution for measured factors within the PAM50 assay by performing repeated measures on four archetypal samples representative of the major breast cancer tumor subtypes. Then, using the error distributions and the original archetypal sample data, we used Monte Carlo simulations to generate a sufficient number of simulated samples. The effect of these errors on the PAM50 tumor subtype classification was estimated by measuring subtype reproducibility after classifying all simulated samples. Subtype reproducibility was measured as the percentage of simulated samples classified identically to the parent sample. The simulation was thereafter repeated on a large, independent data set of samples from the GEICAM 9906 clinical trial. Simulated samples from the GEICAM sample set were used to explore a more realistic scenario where, unlike archetypal samples, many samples are not easily classified.</p><p><strong>Results: </strong>All simulated samples derived from the archetypal samples were classified identically to the parent sample. Subtypes for simulated samples from the GEICAM set were also highly reproducible, but there were a non-negligible number of samples that exhibit significant variability in their classification.</p><p><strong>Conclusions: </strong>We have developed a general methodology to estimate the effects of intrinsic errors within MVAs. We have applied the method to the PAM50 assay, showing that the PAM50 results are resilient to intrinsic errors within the assay, but also finding that in non-archetypal samples, experimental errors can lead to quite different classification of a tumor. Finally we propose a way to provide the uncertainty information in a usable way for clinicians.</p>","PeriodicalId":73663,"journal":{"name":"Journal of clinical bioinformatics","volume":"1 ","pages":"37"},"PeriodicalIF":0.0000,"publicationDate":"2011-12-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/2043-9113-1-37","citationCount":"27","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of clinical bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/2043-9113-1-37","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 27
Abstract
Background: Multivariate assays (MVAs) for assisting clinical decisions are becoming commonly available, but due to complexity, are often considered a high-risk approach. A key concern is that uncertainty on the assay's final results is not well understood. This study focuses on developing a process to characterize error introduced in the MVA's results from the intrinsic error in the laboratory process: sample preparation and measurement of the contributing factors, such as gene expression.
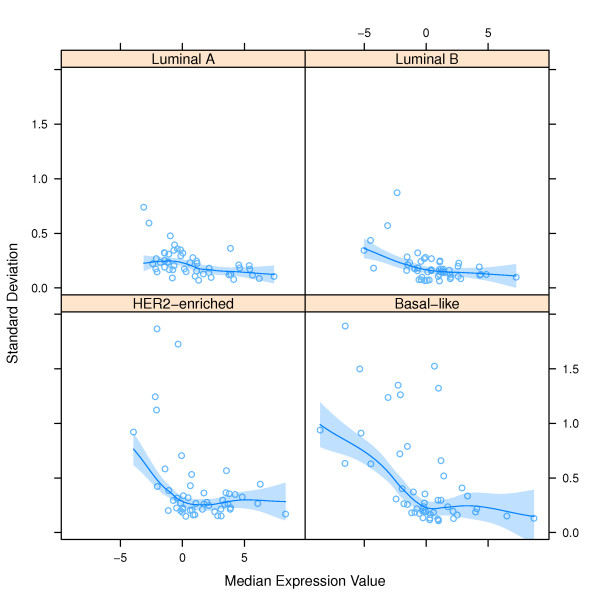
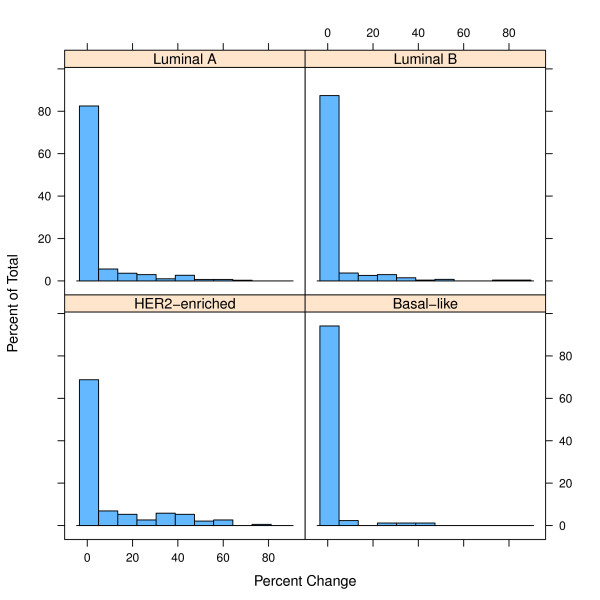
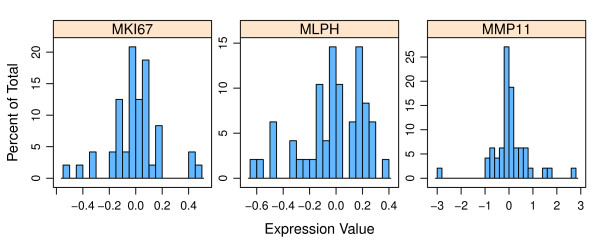
Methods: Using the PAM50 Breast Cancer Intrinsic Classifier, we show how to characterize error within an MVA, and how these errors may affect results reported to clinicians. First we estimated the error distribution for measured factors within the PAM50 assay by performing repeated measures on four archetypal samples representative of the major breast cancer tumor subtypes. Then, using the error distributions and the original archetypal sample data, we used Monte Carlo simulations to generate a sufficient number of simulated samples. The effect of these errors on the PAM50 tumor subtype classification was estimated by measuring subtype reproducibility after classifying all simulated samples. Subtype reproducibility was measured as the percentage of simulated samples classified identically to the parent sample. The simulation was thereafter repeated on a large, independent data set of samples from the GEICAM 9906 clinical trial. Simulated samples from the GEICAM sample set were used to explore a more realistic scenario where, unlike archetypal samples, many samples are not easily classified.
Results: All simulated samples derived from the archetypal samples were classified identically to the parent sample. Subtypes for simulated samples from the GEICAM set were also highly reproducible, but there were a non-negligible number of samples that exhibit significant variability in their classification.
Conclusions: We have developed a general methodology to estimate the effects of intrinsic errors within MVAs. We have applied the method to the PAM50 assay, showing that the PAM50 results are resilient to intrinsic errors within the assay, but also finding that in non-archetypal samples, experimental errors can lead to quite different classification of a tumor. Finally we propose a way to provide the uncertainty information in a usable way for clinicians.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
