Manuela Hische, Abdelhalim Larhlimi, Franziska Schwarz, Antje Fischer-Rosinský, Thomas Bobbert, Anke Assmann, Gareth S Catchpole, Andreas Fh Pfeiffer, Lothar Willmitzer, Joachim Selbig, Joachim Spranger
{"title":"A distinct metabolic signature predicts development of fasting plasma glucose.","authors":"Manuela Hische, Abdelhalim Larhlimi, Franziska Schwarz, Antje Fischer-Rosinský, Thomas Bobbert, Anke Assmann, Gareth S Catchpole, Andreas Fh Pfeiffer, Lothar Willmitzer, Joachim Selbig, Joachim Spranger","doi":"10.1186/2043-9113-2-3","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>High blood glucose and diabetes are amongst the conditions causing the greatest losses in years of healthy life worldwide. Therefore, numerous studies aim to identify reliable risk markers for development of impaired glucose metabolism and type 2 diabetes. However, the molecular basis of impaired glucose metabolism is so far insufficiently understood. The development of so called 'omics' approaches in the recent years promises to identify molecular markers and to further understand the molecular basis of impaired glucose metabolism and type 2 diabetes. Although univariate statistical approaches are often applied, we demonstrate here that the application of multivariate statistical approaches is highly recommended to fully capture the complexity of data gained using high-throughput methods.</p><p><strong>Methods: </strong>We took blood plasma samples from 172 subjects who participated in the prospective Metabolic Syndrome Berlin Potsdam follow-up study (MESY-BEPO Follow-up). We analysed these samples using Gas Chromatography coupled with Mass Spectrometry (GC-MS), and measured 286 metabolites. Furthermore, fasting glucose levels were measured using standard methods at baseline, and after an average of six years. We did correlation analysis and built linear regression models as well as Random Forest regression models to identify metabolites that predict the development of fasting glucose in our cohort.</p><p><strong>Results: </strong>We found a metabolic pattern consisting of nine metabolites that predicted fasting glucose development with an accuracy of 0.47 in tenfold cross-validation using Random Forest regression. We also showed that adding established risk markers did not improve the model accuracy. However, external validation is eventually desirable. Although not all metabolites belonging to the final pattern are identified yet, the pattern directs attention to amino acid metabolism, energy metabolism and redox homeostasis.</p><p><strong>Conclusions: </strong>We demonstrate that metabolites identified using a high-throughput method (GC-MS) perform well in predicting the development of fasting plasma glucose over several years. Notably, not single, but a complex pattern of metabolites propels the prediction and therefore reflects the complexity of the underlying molecular mechanisms. This result could only be captured by application of multivariate statistical approaches. Therefore, we highly recommend the usage of statistical methods that seize the complexity of the information given by high-throughput methods.</p>","PeriodicalId":73663,"journal":{"name":"Journal of clinical bioinformatics","volume":"2 ","pages":"3"},"PeriodicalIF":0.0000,"publicationDate":"2012-02-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/2043-9113-2-3","citationCount":"8","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of clinical bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/2043-9113-2-3","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 8
Abstract
Background: High blood glucose and diabetes are amongst the conditions causing the greatest losses in years of healthy life worldwide. Therefore, numerous studies aim to identify reliable risk markers for development of impaired glucose metabolism and type 2 diabetes. However, the molecular basis of impaired glucose metabolism is so far insufficiently understood. The development of so called 'omics' approaches in the recent years promises to identify molecular markers and to further understand the molecular basis of impaired glucose metabolism and type 2 diabetes. Although univariate statistical approaches are often applied, we demonstrate here that the application of multivariate statistical approaches is highly recommended to fully capture the complexity of data gained using high-throughput methods.
Methods: We took blood plasma samples from 172 subjects who participated in the prospective Metabolic Syndrome Berlin Potsdam follow-up study (MESY-BEPO Follow-up). We analysed these samples using Gas Chromatography coupled with Mass Spectrometry (GC-MS), and measured 286 metabolites. Furthermore, fasting glucose levels were measured using standard methods at baseline, and after an average of six years. We did correlation analysis and built linear regression models as well as Random Forest regression models to identify metabolites that predict the development of fasting glucose in our cohort.
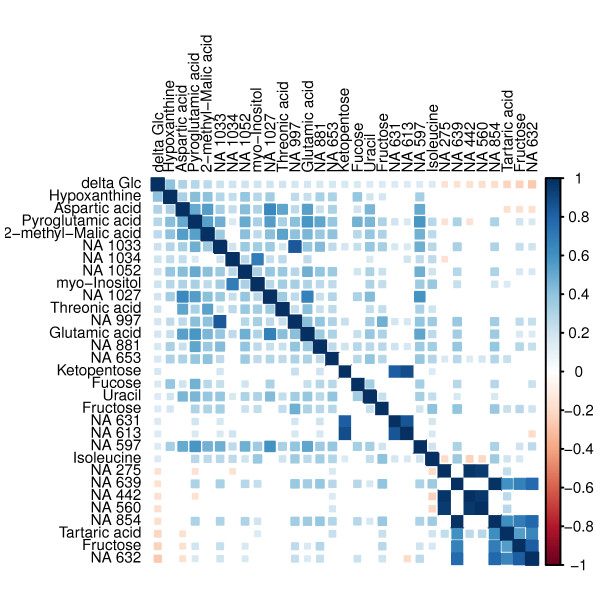
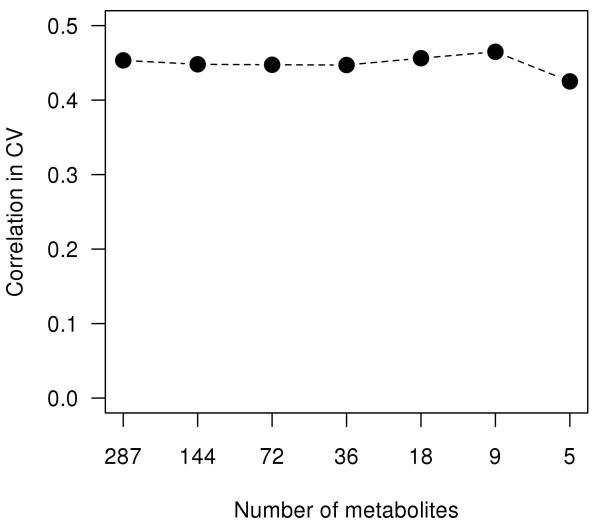
Results: We found a metabolic pattern consisting of nine metabolites that predicted fasting glucose development with an accuracy of 0.47 in tenfold cross-validation using Random Forest regression. We also showed that adding established risk markers did not improve the model accuracy. However, external validation is eventually desirable. Although not all metabolites belonging to the final pattern are identified yet, the pattern directs attention to amino acid metabolism, energy metabolism and redox homeostasis.
Conclusions: We demonstrate that metabolites identified using a high-throughput method (GC-MS) perform well in predicting the development of fasting plasma glucose over several years. Notably, not single, but a complex pattern of metabolites propels the prediction and therefore reflects the complexity of the underlying molecular mechanisms. This result could only be captured by application of multivariate statistical approaches. Therefore, we highly recommend the usage of statistical methods that seize the complexity of the information given by high-throughput methods.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
