Sunghwan Sohn, Cheryl Clark, Scott R Halgrim, Sean P Murphy, Siddhartha R Jonnalagadda, Kavishwar B Wagholikar, Stephen T Wu, Christopher G Chute, Hongfang Liu
{"title":"Analysis of cross-institutional medication description patterns in clinical narratives.","authors":"Sunghwan Sohn, Cheryl Clark, Scott R Halgrim, Sean P Murphy, Siddhartha R Jonnalagadda, Kavishwar B Wagholikar, Stephen T Wu, Christopher G Chute, Hongfang Liu","doi":"10.4137/BII.S11634","DOIUrl":null,"url":null,"abstract":"<p><p>A large amount of medication information resides in the unstructured text found in electronic medical records, which requires advanced techniques to be properly mined. In clinical notes, medication information follows certain semantic patterns (eg, medication, dosage, frequency, and mode). Some medication descriptions contain additional word(s) between medication attributes. Therefore, it is essential to understand the semantic patterns as well as the patterns of the context interspersed among them (ie, context patterns) to effectively extract comprehensive medication information. In this paper we examined both semantic and context patterns, and compared those found in Mayo Clinic and i2b2 challenge data. We found that some variations exist between the institutions but the dominant patterns are common. </p>","PeriodicalId":88397,"journal":{"name":"Biomedical informatics insights","volume":"6 Suppl 1","pages":"7-16"},"PeriodicalIF":0.0000,"publicationDate":"2013-06-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.4137/BII.S11634","citationCount":"13","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biomedical informatics insights","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4137/BII.S11634","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2013/1/1 0:00:00","PubModel":"Print","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 13
Abstract
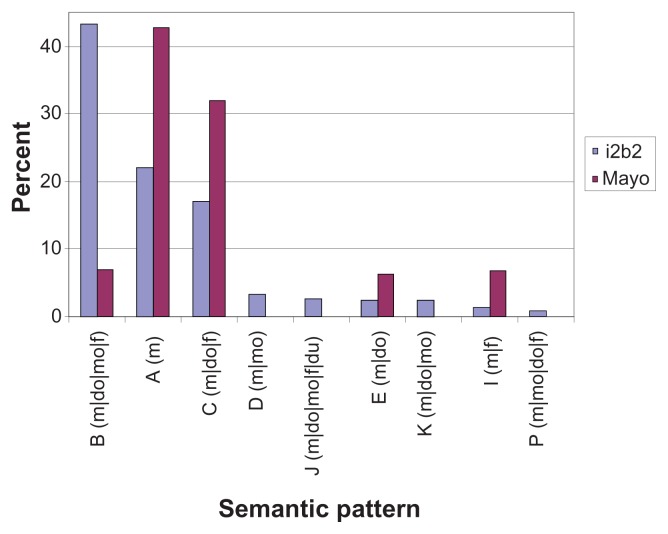
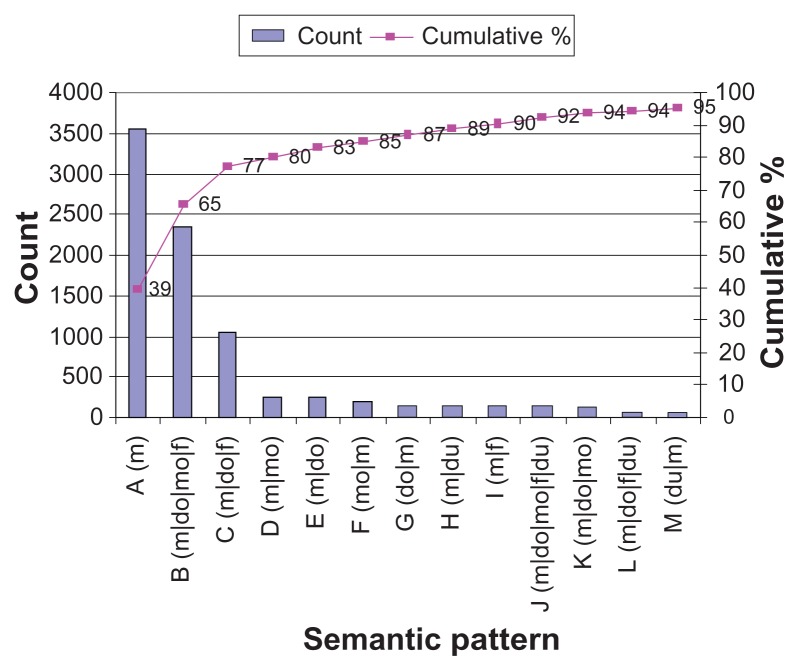
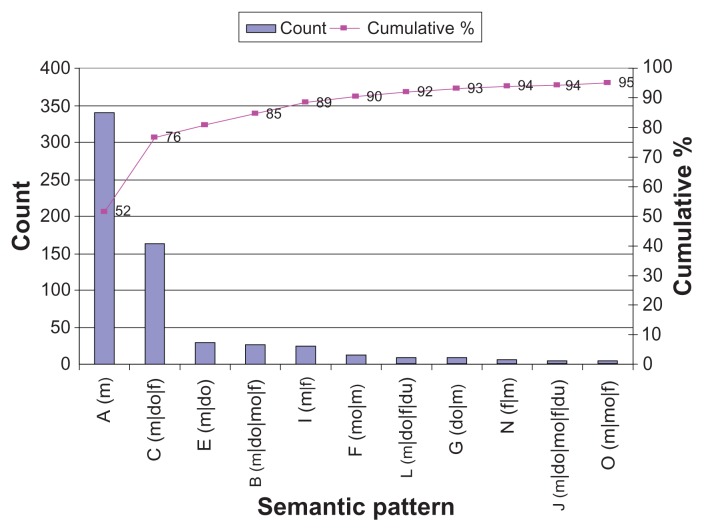
A large amount of medication information resides in the unstructured text found in electronic medical records, which requires advanced techniques to be properly mined. In clinical notes, medication information follows certain semantic patterns (eg, medication, dosage, frequency, and mode). Some medication descriptions contain additional word(s) between medication attributes. Therefore, it is essential to understand the semantic patterns as well as the patterns of the context interspersed among them (ie, context patterns) to effectively extract comprehensive medication information. In this paper we examined both semantic and context patterns, and compared those found in Mayo Clinic and i2b2 challenge data. We found that some variations exist between the institutions but the dominant patterns are common.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
