Three algorithms and SAS macros for estimating power and sample size for logistic models with one or more independent variables of interest in the presence of covariates.
{"title":"Three algorithms and SAS macros for estimating power and sample size for logistic models with one or more independent variables of interest in the presence of covariates.","authors":"David Keith Williams, Zoran Bursac","doi":"10.1186/1751-0473-9-24","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Commonly when designing studies, researchers propose to measure several independent variables in a regression model, a subset of which are identified as the main variables of interest while the rest are retained in a model as covariates or confounders. Power for linear regression in this setting can be calculated using SAS PROC POWER. There exists a void in estimating power for the logistic regression models in the same setting.</p><p><strong>Methods: </strong>Currently, an approach that calculates power for only one variable of interest in the presence of other covariates for logistic regression is in common use and works well for this special case. In this paper we propose three related algorithms along with corresponding SAS macros that extend power estimation for one or more primary variables of interest in the presence of some confounders.</p><p><strong>Results: </strong>The three proposed empirical algorithms employ likelihood ratio test to provide a user with either a power estimate for a given sample size, a quick sample size estimate for a given power, and an approximate power curve for a range of sample sizes. A user can specify odds ratios for a combination of binary, uniform and standard normal independent variables of interest, and or remaining covariates/confounders in the model, along with a correlation between variables.</p><p><strong>Conclusions: </strong>These user friendly algorithms and macro tools are a promising solution that can fill the void for estimation of power for logistic regression when multiple independent variables are of interest, in the presence of additional covariates in the model.</p>","PeriodicalId":35052,"journal":{"name":"Source Code for Biology and Medicine","volume":"9 ","pages":"24"},"PeriodicalIF":0.0000,"publicationDate":"2014-11-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/1751-0473-9-24","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Source Code for Biology and Medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/1751-0473-9-24","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2014/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"Decision Sciences","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Commonly when designing studies, researchers propose to measure several independent variables in a regression model, a subset of which are identified as the main variables of interest while the rest are retained in a model as covariates or confounders. Power for linear regression in this setting can be calculated using SAS PROC POWER. There exists a void in estimating power for the logistic regression models in the same setting.
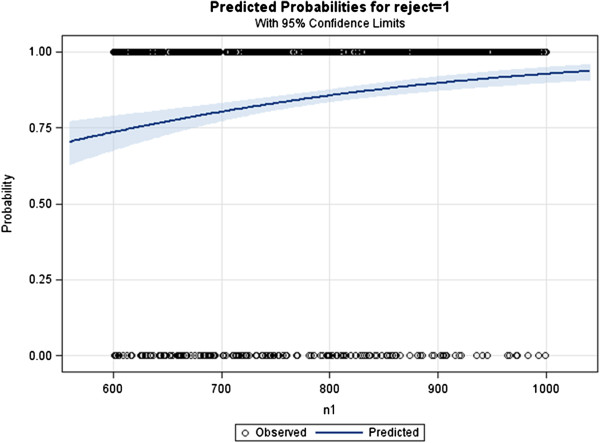
Methods: Currently, an approach that calculates power for only one variable of interest in the presence of other covariates for logistic regression is in common use and works well for this special case. In this paper we propose three related algorithms along with corresponding SAS macros that extend power estimation for one or more primary variables of interest in the presence of some confounders.
Results: The three proposed empirical algorithms employ likelihood ratio test to provide a user with either a power estimate for a given sample size, a quick sample size estimate for a given power, and an approximate power curve for a range of sample sizes. A user can specify odds ratios for a combination of binary, uniform and standard normal independent variables of interest, and or remaining covariates/confounders in the model, along with a correlation between variables.
Conclusions: These user friendly algorithms and macro tools are a promising solution that can fill the void for estimation of power for logistic regression when multiple independent variables are of interest, in the presence of additional covariates in the model.
期刊介绍:
Source Code for Biology and Medicine is a peer-reviewed open access, online journal that publishes articles on source code employed over a wide range of applications in biology and medicine. The journal"s aim is to publish source code for distribution and use in the public domain in order to advance biological and medical research. Through this dissemination, it may be possible to shorten the time required for solving certain computational problems for which there is limited source code availability or resources.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
