{"title":"Machine Learning Algorithms for understanding the determinants of under-five Mortality.","authors":"Rakesh Kumar Saroj, Pawan Kumar Yadav, Rajneesh Singh, Obvious N Chilyabanyama","doi":"10.1186/s13040-022-00308-8","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Under-five mortality is a matter of serious concern for child health as well as the social development of any country. The paper aimed to find the accuracy of machine learning models in predicting under-five mortality and identify the most significant factors associated with under-five mortality.</p><p><strong>Method: </strong>The data was taken from the National Family Health Survey (NFHS-IV) of Uttar Pradesh. First, we used multivariate logistic regression due to its capability for predicting the important factors, then we used machine learning techniques such as decision tree, random forest, Naïve Bayes, K- nearest neighbor (KNN), logistic regression, support vector machine (SVM), neural network, and ridge classifier. Each model's accuracy was checked by a confusion matrix, accuracy, precision, recall, F1 score, Cohen's Kappa, and area under the receiver operating characteristics curve (AUROC). Information gain rank was used to find the important factors for under-five mortality. Data analysis was performed using, STATA-16.0, Python 3.3, and IBM SPSS Statistics for Windows, Version 27.0 software.</p><p><strong>Result: </strong>By applying the machine learning models, results showed that the neural network model was the best predictive model for under-five mortality when compared with other predictive models, with model accuracy of (95.29% to 95.96%), recall (71.51% to 81.03%), precision (36.64% to 51.83%), F1 score (50.46% to 62.68%), Cohen's Kappa value (0.48 to 0.60), AUROC range (93.51% to 96.22%) and precision-recall curve range (99.52% to 99.73%). The neural network was the most efficient model, but logistic regression also shows well for predicting under-five mortality with accuracy (94% to 95%)., AUROC range (93.4% to 94.8%), and precision-recall curve (99.5% to 99.6%). The number of living children, survival time, wealth index, child size at birth, birth in the last five years, the total number of children ever born, mother's education level, and birth order were identified as important factors influencing under-five mortality.</p><p><strong>Conclusion: </strong>The neural network model was a better predictive model compared to other machine learning models in predicting under-five mortality, but logistic regression analysis also shows good results. These models may be helpful for the analysis of high-dimensional data for health research.</p>","PeriodicalId":4,"journal":{"name":"ACS Applied Energy Materials","volume":" ","pages":"20"},"PeriodicalIF":5.5000,"publicationDate":"2022-09-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9509654/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"ACS Applied Energy Materials","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-022-00308-8","RegionNum":3,"RegionCategory":"材料科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"CHEMISTRY, PHYSICAL","Score":null,"Total":0}
引用次数: 0
Abstract
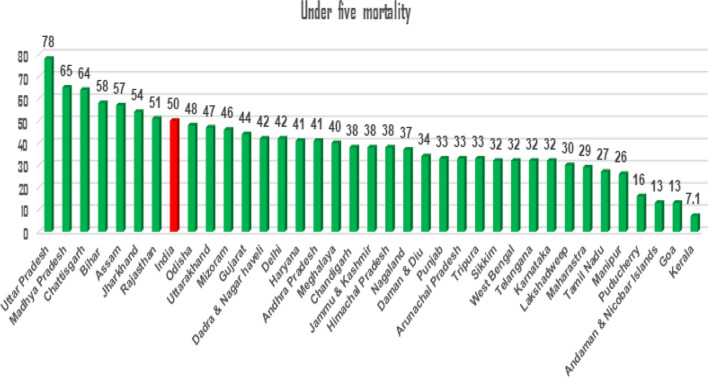
Background: Under-five mortality is a matter of serious concern for child health as well as the social development of any country. The paper aimed to find the accuracy of machine learning models in predicting under-five mortality and identify the most significant factors associated with under-five mortality.
Method: The data was taken from the National Family Health Survey (NFHS-IV) of Uttar Pradesh. First, we used multivariate logistic regression due to its capability for predicting the important factors, then we used machine learning techniques such as decision tree, random forest, Naïve Bayes, K- nearest neighbor (KNN), logistic regression, support vector machine (SVM), neural network, and ridge classifier. Each model's accuracy was checked by a confusion matrix, accuracy, precision, recall, F1 score, Cohen's Kappa, and area under the receiver operating characteristics curve (AUROC). Information gain rank was used to find the important factors for under-five mortality. Data analysis was performed using, STATA-16.0, Python 3.3, and IBM SPSS Statistics for Windows, Version 27.0 software.
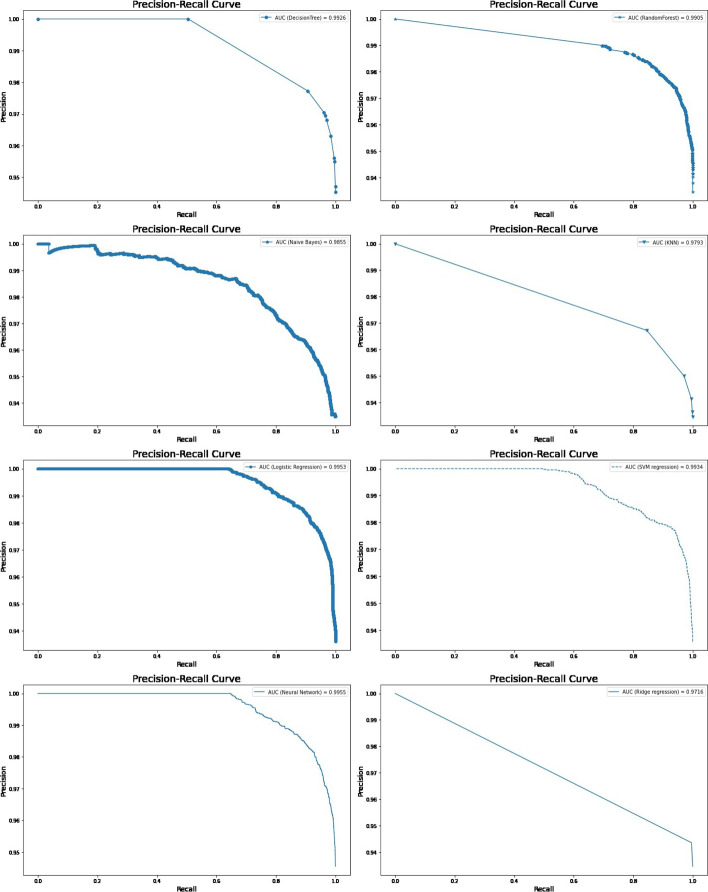
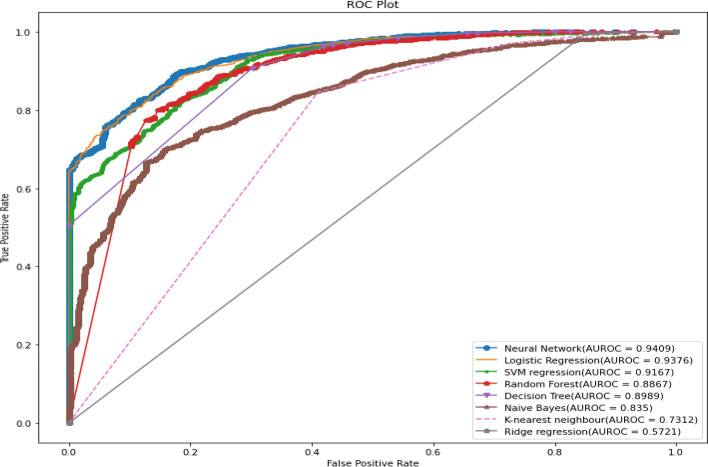
Result: By applying the machine learning models, results showed that the neural network model was the best predictive model for under-five mortality when compared with other predictive models, with model accuracy of (95.29% to 95.96%), recall (71.51% to 81.03%), precision (36.64% to 51.83%), F1 score (50.46% to 62.68%), Cohen's Kappa value (0.48 to 0.60), AUROC range (93.51% to 96.22%) and precision-recall curve range (99.52% to 99.73%). The neural network was the most efficient model, but logistic regression also shows well for predicting under-five mortality with accuracy (94% to 95%)., AUROC range (93.4% to 94.8%), and precision-recall curve (99.5% to 99.6%). The number of living children, survival time, wealth index, child size at birth, birth in the last five years, the total number of children ever born, mother's education level, and birth order were identified as important factors influencing under-five mortality.
Conclusion: The neural network model was a better predictive model compared to other machine learning models in predicting under-five mortality, but logistic regression analysis also shows good results. These models may be helpful for the analysis of high-dimensional data for health research.
期刊介绍:
ACS Applied Energy Materials is an interdisciplinary journal publishing original research covering all aspects of materials, engineering, chemistry, physics and biology relevant to energy conversion and storage. The journal is devoted to reports of new and original experimental and theoretical research of an applied nature that integrate knowledge in the areas of materials, engineering, physics, bioscience, and chemistry into important energy applications.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
