{"title":"Quick and clean: Cracking sentences encoded in E. coli by LC–MS/MS, de novo sequencing, and dictionary search","authors":"Lili Niu , Matthias Mann","doi":"10.1016/j.euprot.2019.07.010","DOIUrl":null,"url":null,"abstract":"<div><p>In this study, we faced the challenge of deciphering a protein that has been designed and expressed by <em>E. coli</em> in such a way that the amino acid sequence encodes two concatenated English sentences. The letters ‘O’ and ‘U’ in the sentence are both replaced by ‘K’ in the protein. The sequence cannot be found online and carried to-be-discovered modifications. With limited information in hand, to solve the challenge, we developed a workflow consisting of bottom-up proteomics, de novo sequencing and a bioinformatics pipeline for data processing and searching for frequently appearing words. We assembled a complete first question: “Have you ever wondered what the most fundamental limitations in life are?” and validated the result by sequence database search against a customized FASTA file. We also searched the spectra against an <em>E. coli</em> proteome database and found close to 600 endogenous, co-purified <em>E. coli</em> proteins and contaminants introduced during sample handling, which made the inference of the sentence very challenging. We conclude that <em>E. coli</em> can express English sentences, and that de novo sequencing combined with clever sequence database search strategies is a promising tool for the identification of uncharacterized proteins.</p></div>","PeriodicalId":38260,"journal":{"name":"EuPA Open Proteomics","volume":"22 ","pages":"Pages 30-35"},"PeriodicalIF":0.0000,"publicationDate":"2019-03-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1016/j.euprot.2019.07.010","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"EuPA Open Proteomics","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2212968519300145","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"Biochemistry, Genetics and Molecular Biology","Score":null,"Total":0}
引用次数: 2
Abstract
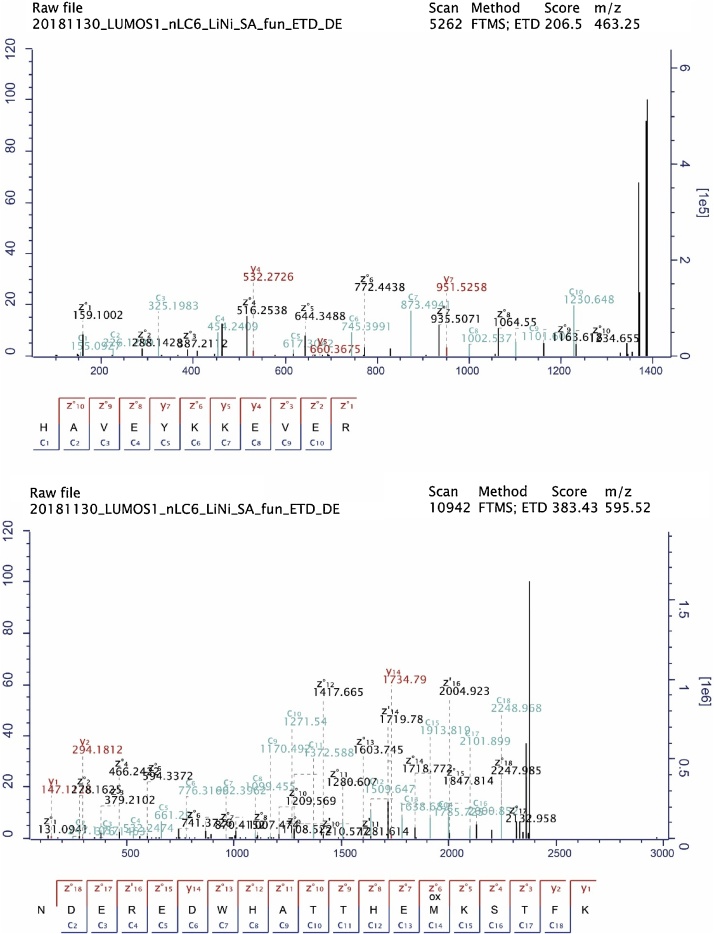
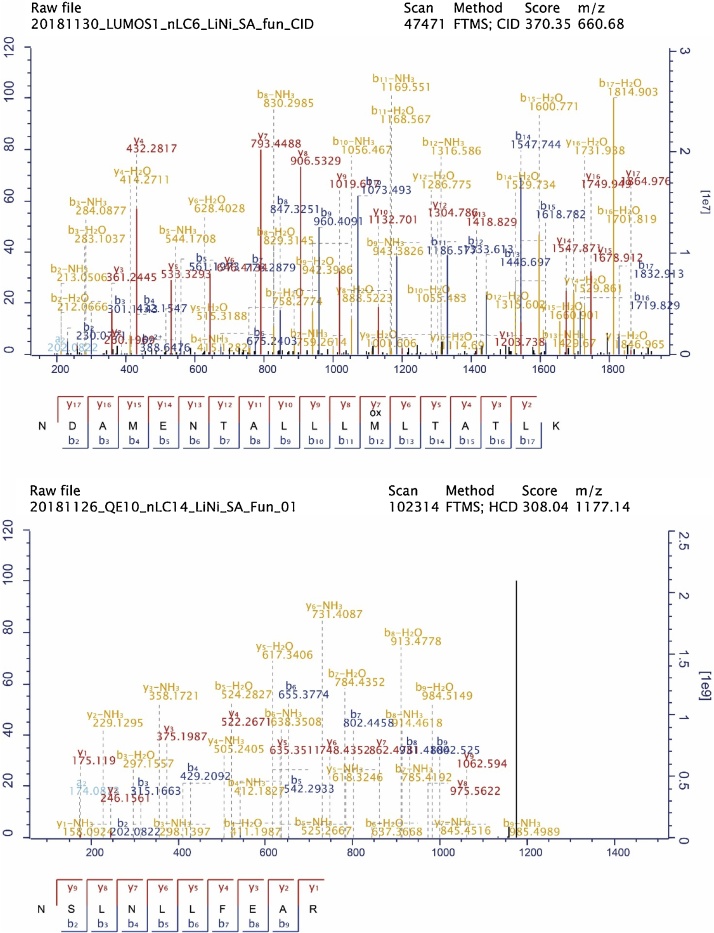
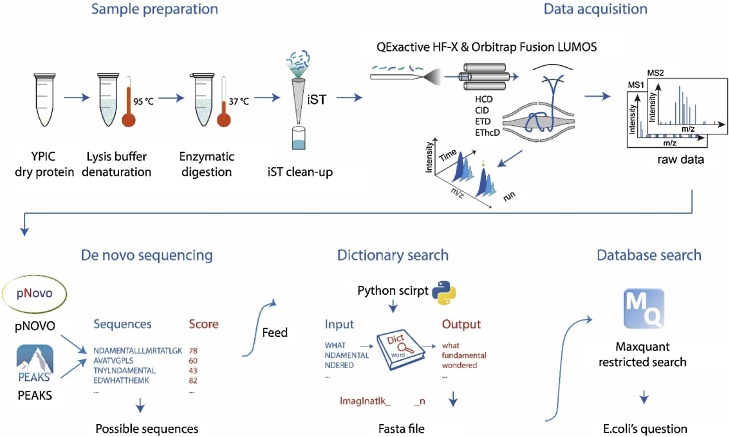
In this study, we faced the challenge of deciphering a protein that has been designed and expressed by E. coli in such a way that the amino acid sequence encodes two concatenated English sentences. The letters ‘O’ and ‘U’ in the sentence are both replaced by ‘K’ in the protein. The sequence cannot be found online and carried to-be-discovered modifications. With limited information in hand, to solve the challenge, we developed a workflow consisting of bottom-up proteomics, de novo sequencing and a bioinformatics pipeline for data processing and searching for frequently appearing words. We assembled a complete first question: “Have you ever wondered what the most fundamental limitations in life are?” and validated the result by sequence database search against a customized FASTA file. We also searched the spectra against an E. coli proteome database and found close to 600 endogenous, co-purified E. coli proteins and contaminants introduced during sample handling, which made the inference of the sentence very challenging. We conclude that E. coli can express English sentences, and that de novo sequencing combined with clever sequence database search strategies is a promising tool for the identification of uncharacterized proteins.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
