The development and validation of prognostic models for overall survival in the presence of missing data in the training dataset: a strategy with a detailed example.
{"title":"The development and validation of prognostic models for overall survival in the presence of missing data in the training dataset: a strategy with a detailed example.","authors":"Kara-Louise Royle, David A Cairns","doi":"10.1186/s41512-021-00103-9","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The United Kingdom Myeloma Research Alliance (UK-MRA) Myeloma Risk Profile is a prognostic model for overall survival. It was trained and tested on clinical trial data, aiming to improve the stratification of transplant ineligible (TNE) patients with newly diagnosed multiple myeloma. Missing data is a common problem which affects the development and validation of prognostic models, where decisions on how to address missingness have implications on the choice of methodology.</p><p><strong>Methods: </strong>Model building The training and test datasets were the TNE pathways from two large randomised multicentre, phase III clinical trials. Potential prognostic factors were identified by expert opinion. Missing data in the training dataset was imputed using multiple imputation by chained equations. Univariate analysis fitted Cox proportional hazards models in each imputed dataset with the estimates combined by Rubin's rules. Multivariable analysis applied penalised Cox regression models, with a fixed penalty term across the imputed datasets. The estimates from each imputed dataset and bootstrap standard errors were combined by Rubin's rules to define the prognostic model. Model assessment Calibration was assessed by visualising the observed and predicted probabilities across the imputed datasets. Discrimination was assessed by combining the prognostic separation D-statistic from each imputed dataset by Rubin's rules. Model validation The D-statistic was applied in a bootstrap internal validation process in the training dataset and an external validation process in the test dataset, where acceptable performance was pre-specified. Development of risk groups Risk groups were defined using the tertiles of the combined prognostic index, obtained by combining the prognostic index from each imputed dataset by Rubin's rules.</p><p><strong>Results: </strong>The training dataset included 1852 patients, 1268 (68.47%) with complete case data. Ten imputed datasets were generated. Five hundred twenty patients were included in the test dataset. The D-statistic for the prognostic model was 0.840 (95% CI 0.716-0.964) in the training dataset and 0.654 (95% CI 0.497-0.811) in the test dataset and the corrected D-Statistic was 0.801.</p><p><strong>Conclusion: </strong>The decision to impute missing covariate data in the training dataset influenced the methods implemented to train and test the model. To extend current literature and aid future researchers, we have presented a detailed example of one approach. Whilst our example is not without limitations, a benefit is that all of the patient information available in the training dataset was utilised to develop the model.</p><p><strong>Trial registration: </strong>Both trials were registered; Myeloma IX- ISRCTN68454111 , registered 21 September 2000. Myeloma XI- ISRCTN49407852 , registered 24 June 2009.</p>","PeriodicalId":72800,"journal":{"name":"Diagnostic and prognostic research","volume":" ","pages":"14"},"PeriodicalIF":2.6000,"publicationDate":"2021-08-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8335879/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Diagnostic and prognostic research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s41512-021-00103-9","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The United Kingdom Myeloma Research Alliance (UK-MRA) Myeloma Risk Profile is a prognostic model for overall survival. It was trained and tested on clinical trial data, aiming to improve the stratification of transplant ineligible (TNE) patients with newly diagnosed multiple myeloma. Missing data is a common problem which affects the development and validation of prognostic models, where decisions on how to address missingness have implications on the choice of methodology.
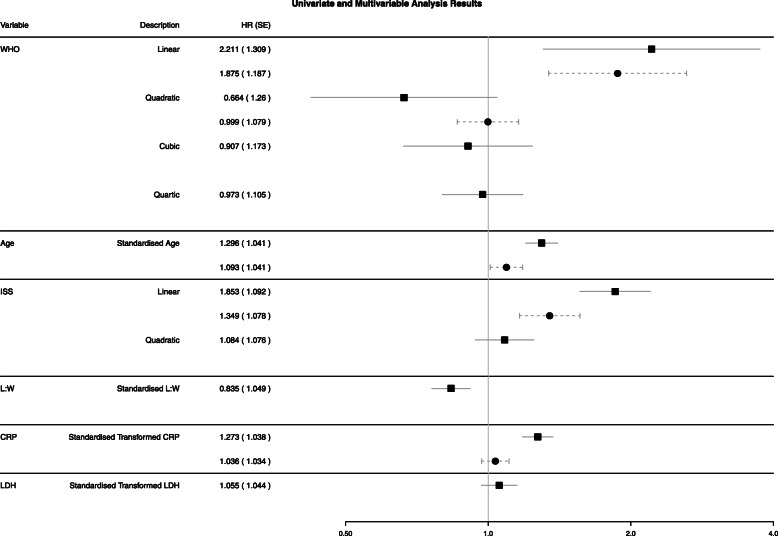
Methods: Model building The training and test datasets were the TNE pathways from two large randomised multicentre, phase III clinical trials. Potential prognostic factors were identified by expert opinion. Missing data in the training dataset was imputed using multiple imputation by chained equations. Univariate analysis fitted Cox proportional hazards models in each imputed dataset with the estimates combined by Rubin's rules. Multivariable analysis applied penalised Cox regression models, with a fixed penalty term across the imputed datasets. The estimates from each imputed dataset and bootstrap standard errors were combined by Rubin's rules to define the prognostic model. Model assessment Calibration was assessed by visualising the observed and predicted probabilities across the imputed datasets. Discrimination was assessed by combining the prognostic separation D-statistic from each imputed dataset by Rubin's rules. Model validation The D-statistic was applied in a bootstrap internal validation process in the training dataset and an external validation process in the test dataset, where acceptable performance was pre-specified. Development of risk groups Risk groups were defined using the tertiles of the combined prognostic index, obtained by combining the prognostic index from each imputed dataset by Rubin's rules.
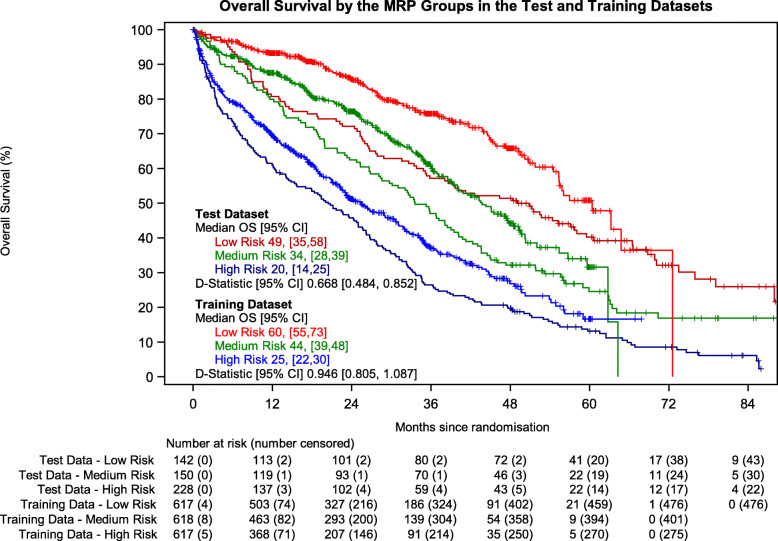
Results: The training dataset included 1852 patients, 1268 (68.47%) with complete case data. Ten imputed datasets were generated. Five hundred twenty patients were included in the test dataset. The D-statistic for the prognostic model was 0.840 (95% CI 0.716-0.964) in the training dataset and 0.654 (95% CI 0.497-0.811) in the test dataset and the corrected D-Statistic was 0.801.
Conclusion: The decision to impute missing covariate data in the training dataset influenced the methods implemented to train and test the model. To extend current literature and aid future researchers, we have presented a detailed example of one approach. Whilst our example is not without limitations, a benefit is that all of the patient information available in the training dataset was utilised to develop the model.
Trial registration: Both trials were registered; Myeloma IX- ISRCTN68454111 , registered 21 September 2000. Myeloma XI- ISRCTN49407852 , registered 24 June 2009.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
