Márcia Barros, Pedro Ruas, Diana Sousa, Ali Haider Bangash, Francisco M Couto
{"title":"COVID-19 recommender system based on an annotated multilingual corpus.","authors":"Márcia Barros, Pedro Ruas, Diana Sousa, Ali Haider Bangash, Francisco M Couto","doi":"10.5808/gi.21008","DOIUrl":null,"url":null,"abstract":"<p><p>Tracking the most recent advances in Coronavirus disease 2019 (COVID-19)-related research is essential, given the disease's novelty and its impact on society. However, with the publication pace speeding up, researchers and clinicians require automatic approaches to keep up with the incoming information regarding this disease. A solution to this problem requires the development of text mining pipelines; the efficiency of which strongly depends on the availability of curated corpora. However, there is a lack of COVID-19-related corpora, even more, if considering other languages besides English. This project's main contribution was the annotation of a multilingual parallel corpus and the generation of a recommendation dataset (EN-PT and EN-ES) regarding relevant entities, their relations, and recommendation, providing this resource to the community to improve the text mining research on COVID-19-related literature. This work was developed during the 7th Biomedical Linked Annotation Hackathon (BLAH7).</p>","PeriodicalId":36591,"journal":{"name":"Genomics and Informatics","volume":"19 3","pages":"e24"},"PeriodicalIF":0.0000,"publicationDate":"2021-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8510867/pdf/","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Genomics and Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.5808/gi.21008","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/9/30 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"Agricultural and Biological Sciences","Score":null,"Total":0}
引用次数: 1
Abstract
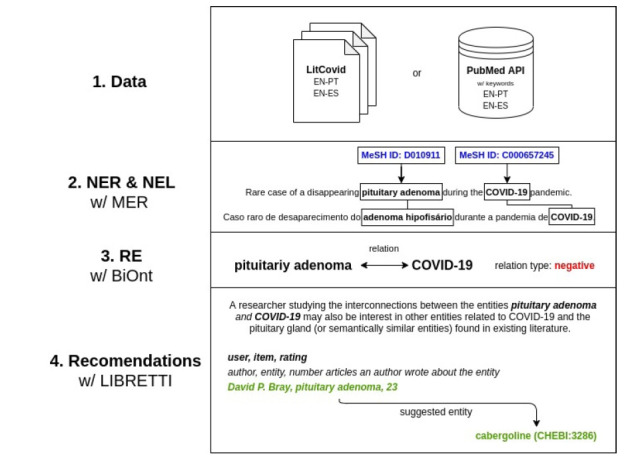
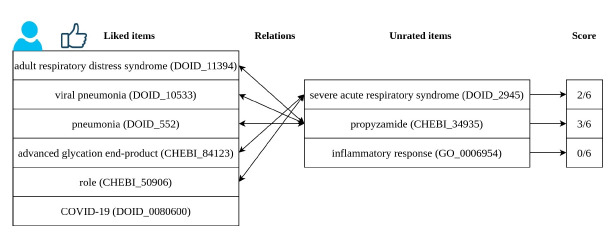
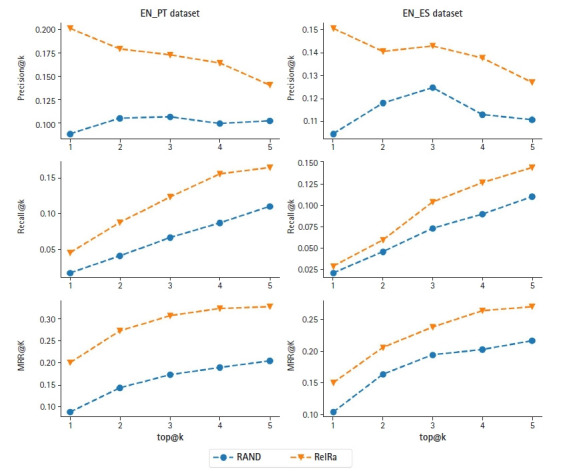
Tracking the most recent advances in Coronavirus disease 2019 (COVID-19)-related research is essential, given the disease's novelty and its impact on society. However, with the publication pace speeding up, researchers and clinicians require automatic approaches to keep up with the incoming information regarding this disease. A solution to this problem requires the development of text mining pipelines; the efficiency of which strongly depends on the availability of curated corpora. However, there is a lack of COVID-19-related corpora, even more, if considering other languages besides English. This project's main contribution was the annotation of a multilingual parallel corpus and the generation of a recommendation dataset (EN-PT and EN-ES) regarding relevant entities, their relations, and recommendation, providing this resource to the community to improve the text mining research on COVID-19-related literature. This work was developed during the 7th Biomedical Linked Annotation Hackathon (BLAH7).



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
