Addressing missing values in routine health information system data: an evaluation of imputation methods using data from the Democratic Republic of the Congo during the COVID-19 pandemic.
{"title":"Addressing missing values in routine health information system data: an evaluation of imputation methods using data from the Democratic Republic of the Congo during the COVID-19 pandemic.","authors":"Shuo Feng, Celestin Hategeka, Karen Ann Grépin","doi":"10.1186/s12963-021-00274-z","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Poor data quality is limiting the use of data sourced from routine health information systems (RHIS), especially in low- and middle-income countries. An important component of this data quality issue comes from missing values, where health facilities, for a variety of reasons, fail to report to the central system.</p><p><strong>Methods: </strong>Using data from the health management information system in the Democratic Republic of the Congo and the advent of COVID-19 pandemic as an illustrative case study, we implemented seven commonly used imputation methods and evaluated their performance in terms of minimizing bias in imputed values and parameter estimates generated through subsequent analytical techniques, namely segmented regression, which is widely used in interrupted time series studies, and pre-post-comparisons through paired Wilcoxon rank-sum tests. We also examined the performance of these imputation methods under different missing mechanisms and tested their stability to changes in the data.</p><p><strong>Results: </strong>For regression analyses, there were no substantial differences found in the coefficient estimates generated from all methods except mean imputation and exclusion and interpolation when the data contained less than 20% missing values. However, as the missing proportion grew, k-NN started to produce biased estimates. Machine learning algorithms, i.e. missForest and k-NN, were also found to lack robustness to small changes in the data or consecutive missingness. On the other hand, multiple imputation methods generated the overall most unbiased estimates and were the most robust to all changes in data. They also produced smaller standard errors than single imputations. For pre-post-comparisons, all methods produced p values less than 0.01, regardless of the amount of missingness introduced, suggesting low sensitivity of Wilcoxon rank-sum tests to the imputation method used.</p><p><strong>Conclusions: </strong>We recommend the use of multiple imputation in addressing missing values in RHIS datasets and appropriate handling of data structure to minimize imputation standard errors. In cases where necessary computing resources are unavailable for multiple imputation, one may consider seasonal decomposition as the next best method. Mean imputation and exclusion and interpolation, however, always produced biased and misleading results in the subsequent analyses, and thus, their use in the handling of missing values should be discouraged.</p>","PeriodicalId":51476,"journal":{"name":"Population Health Metrics","volume":" ","pages":"44"},"PeriodicalIF":2.5000,"publicationDate":"2021-11-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8567342/pdf/","citationCount":"8","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Population Health Metrics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s12963-021-00274-z","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PUBLIC, ENVIRONMENTAL & OCCUPATIONAL HEALTH","Score":null,"Total":0}
引用次数: 8
Abstract
Background: Poor data quality is limiting the use of data sourced from routine health information systems (RHIS), especially in low- and middle-income countries. An important component of this data quality issue comes from missing values, where health facilities, for a variety of reasons, fail to report to the central system.
Methods: Using data from the health management information system in the Democratic Republic of the Congo and the advent of COVID-19 pandemic as an illustrative case study, we implemented seven commonly used imputation methods and evaluated their performance in terms of minimizing bias in imputed values and parameter estimates generated through subsequent analytical techniques, namely segmented regression, which is widely used in interrupted time series studies, and pre-post-comparisons through paired Wilcoxon rank-sum tests. We also examined the performance of these imputation methods under different missing mechanisms and tested their stability to changes in the data.
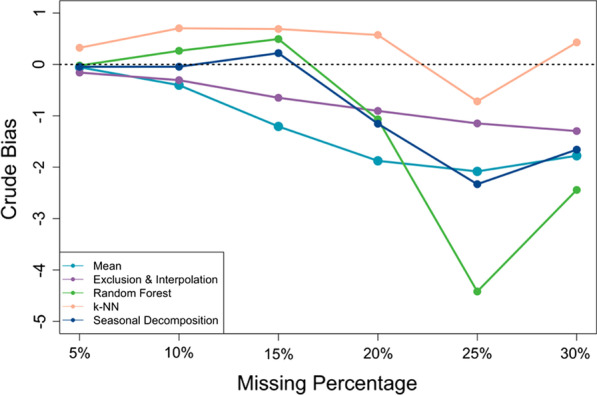
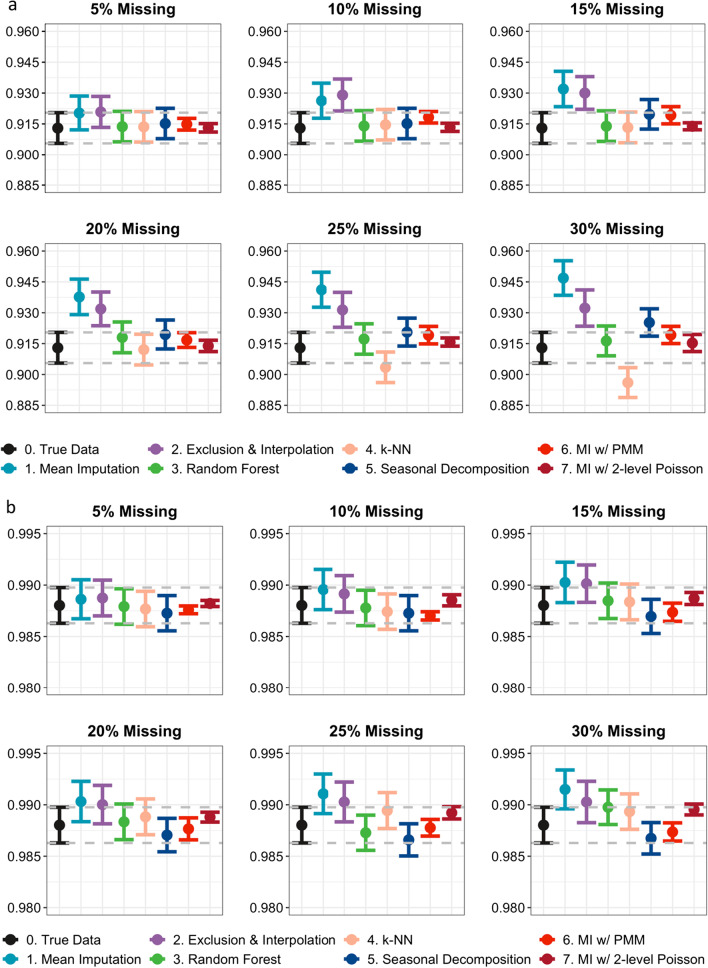
Results: For regression analyses, there were no substantial differences found in the coefficient estimates generated from all methods except mean imputation and exclusion and interpolation when the data contained less than 20% missing values. However, as the missing proportion grew, k-NN started to produce biased estimates. Machine learning algorithms, i.e. missForest and k-NN, were also found to lack robustness to small changes in the data or consecutive missingness. On the other hand, multiple imputation methods generated the overall most unbiased estimates and were the most robust to all changes in data. They also produced smaller standard errors than single imputations. For pre-post-comparisons, all methods produced p values less than 0.01, regardless of the amount of missingness introduced, suggesting low sensitivity of Wilcoxon rank-sum tests to the imputation method used.
Conclusions: We recommend the use of multiple imputation in addressing missing values in RHIS datasets and appropriate handling of data structure to minimize imputation standard errors. In cases where necessary computing resources are unavailable for multiple imputation, one may consider seasonal decomposition as the next best method. Mean imputation and exclusion and interpolation, however, always produced biased and misleading results in the subsequent analyses, and thus, their use in the handling of missing values should be discouraged.
期刊介绍:
Population Health Metrics aims to advance the science of population health assessment, and welcomes papers relating to concepts, methods, ethics, applications, and summary measures of population health. The journal provides a unique platform for population health researchers to share their findings with the global community. We seek research that addresses the communication of population health measures and policy implications to stakeholders; this includes papers related to burden estimation and risk assessment, and research addressing population health across the full range of development. Population Health Metrics covers a broad range of topics encompassing health state measurement and valuation, summary measures of population health, descriptive epidemiology at the population level, burden of disease and injury analysis, disease and risk factor modeling for populations, and comparative assessment of risks to health at the population level. The journal is also interested in how to use and communicate indicators of population health to reduce disease burden, and the approaches for translating from indicators of population health to health-advancing actions. As a cross-cutting topic of importance, we are particularly interested in inequalities in population health and their measurement.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
