{"title":"An optimized FM-index library for nucleotide and amino acid search.","authors":"Tim Anderson, Travis J Wheeler","doi":"10.1186/s13015-021-00204-6","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Pattern matching is a key step in a variety of biological sequence analysis pipelines. The FM-index is a compressed data structure for pattern matching, with search run time that is independent of the length of the database text. Implementation of the FM-index is reasonably complicated, so that increased adoption will be aided by the availability of a fast and flexible FM-index library.</p><p><strong>Results: </strong>We present AvxWindowedFMindex (AWFM-index), a lightweight, open-source, thread-parallel FM-index library written in C that is optimized for indexing nucleotide and amino acid sequences. AWFM-index introduces a new approach to storing FM-index data in a strided bit-vector format that enables extremely efficient computation of the FM-index occurrence function via AVX2 bitwise instructions, and combines this with optional on-disk storage of the index's suffix array and a cache-efficient lookup table for partial k-mer searches. The AWFM-index performs exact match count and locate queries faster than SeqAn3's FM-index implementation across a range of comparable memory footprints. When optimized for speed, AWFM-index is [Formula: see text]2-4x faster than SeqAn3 for nucleotide search, and [Formula: see text]2-6x faster for amino acid search; it is also [Formula: see text]4x faster with similar memory footprint when storing the suffix array in on-disk SSD storage.</p><p><strong>Conclusions: </strong>AWFM-index is easy to incorporate into bioinformatics software, offers run-time performance parameterization, and provides clients with FM-index functionality at both a high-level (count or locate all instances of a query string) and low-level (step-wise control of the FM-index backward-search process). The open-source library is available for download at https://github.com/TravisWheelerLab/AvxWindowFmIndex.</p>","PeriodicalId":72149,"journal":{"name":"","volume":"16 1","pages":"25"},"PeriodicalIF":0.0,"publicationDate":"2021-12-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8719400/pdf/","citationCount":"3","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13015-021-00204-6","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 3
Abstract
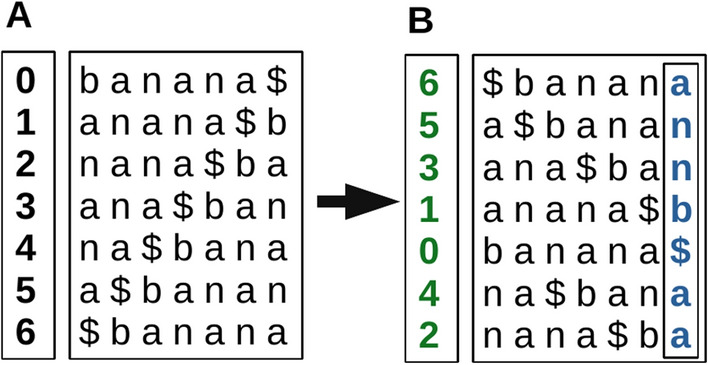
Background: Pattern matching is a key step in a variety of biological sequence analysis pipelines. The FM-index is a compressed data structure for pattern matching, with search run time that is independent of the length of the database text. Implementation of the FM-index is reasonably complicated, so that increased adoption will be aided by the availability of a fast and flexible FM-index library.
Results: We present AvxWindowedFMindex (AWFM-index), a lightweight, open-source, thread-parallel FM-index library written in C that is optimized for indexing nucleotide and amino acid sequences. AWFM-index introduces a new approach to storing FM-index data in a strided bit-vector format that enables extremely efficient computation of the FM-index occurrence function via AVX2 bitwise instructions, and combines this with optional on-disk storage of the index's suffix array and a cache-efficient lookup table for partial k-mer searches. The AWFM-index performs exact match count and locate queries faster than SeqAn3's FM-index implementation across a range of comparable memory footprints. When optimized for speed, AWFM-index is [Formula: see text]2-4x faster than SeqAn3 for nucleotide search, and [Formula: see text]2-6x faster for amino acid search; it is also [Formula: see text]4x faster with similar memory footprint when storing the suffix array in on-disk SSD storage.
Conclusions: AWFM-index is easy to incorporate into bioinformatics software, offers run-time performance parameterization, and provides clients with FM-index functionality at both a high-level (count or locate all instances of a query string) and low-level (step-wise control of the FM-index backward-search process). The open-source library is available for download at https://github.com/TravisWheelerLab/AvxWindowFmIndex.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
