{"title":"OFP-TM: an online VM failure prediction and tolerance model towards high availability of cloud computing environments.","authors":"Deepika Saxena, Ashutosh Kumar Singh","doi":"10.1007/s11227-021-04235-z","DOIUrl":null,"url":null,"abstract":"<p><p>The indispensable collaboration of cloud computing in every digital service has raised its resource usage exponentially. The ever-growing demand of cloud resources evades service availability leading to critical challenges such as cloud outages, SLA violation, and excessive power consumption. Previous approaches have addressed this problem by utilizing multiple cloud platforms or running multiple replicas of a Virtual Machine (VM) resulting into high operational cost. This paper has addressed this alarming problem from a different perspective by proposing a novel <math><mi>O</mi></math> nline virtual machine <math><mi>F</mi></math> ailure <math><mi>P</mi></math> rediction and <math><mi>T</mi></math> olerance <math><mi>M</mi></math> odel (OFP-TM) with high availability awareness embedded in physical machines as well as virtual machines. The failure-prone VMs are estimated in real-time based on their future resource usage by developing an ensemble approach-based resource predictor. These VMs are assigned to a failure tolerance unit comprising of a resource provision matrix and Selection Box (S-Box) mechanism which triggers the migration of failure-prone VMs and handle any outage beforehand while maintaining the desired level of availability for cloud users. The proposed model is evaluated and compared against existing related approaches by simulating cloud environment and executing several experiments using a real-world workload Google Cluster dataset. Consequently, it has been concluded that OFP-TM improves availability and scales down the number of live VM migrations up to 33.5% and 83.3%, respectively, over without OFP-TM.</p>","PeriodicalId":50034,"journal":{"name":"Journal of Supercomputing","volume":"78 6","pages":"8003-8024"},"PeriodicalIF":2.7000,"publicationDate":"2022-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8731188/pdf/","citationCount":"13","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Supercomputing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11227-021-04235-z","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/1/6 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE","Score":null,"Total":0}
引用次数: 13
Abstract
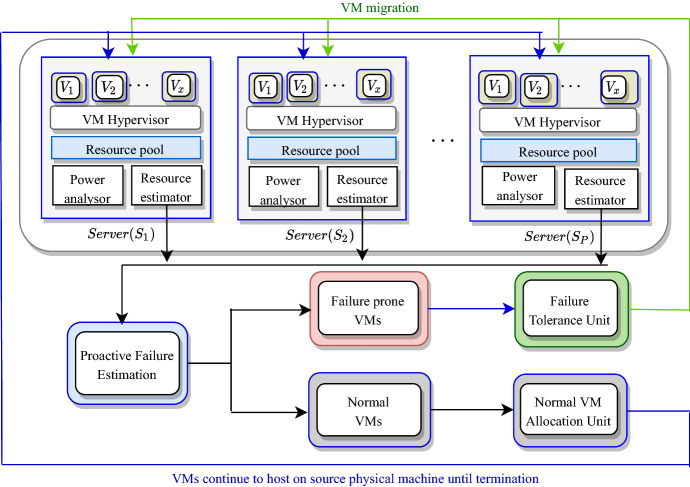
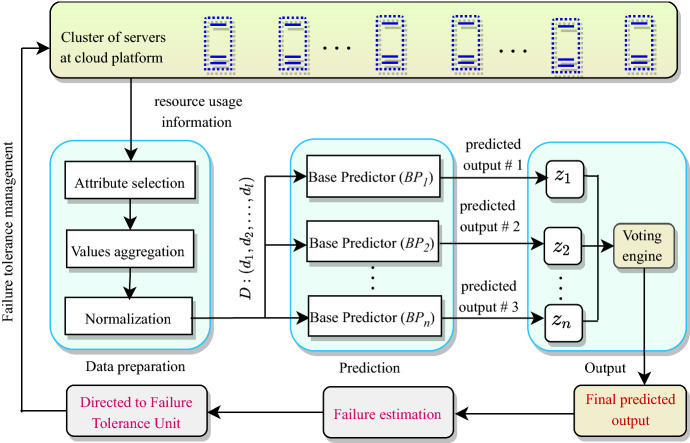
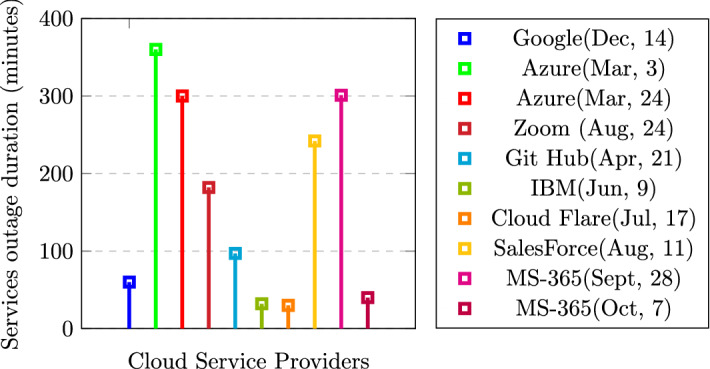
The indispensable collaboration of cloud computing in every digital service has raised its resource usage exponentially. The ever-growing demand of cloud resources evades service availability leading to critical challenges such as cloud outages, SLA violation, and excessive power consumption. Previous approaches have addressed this problem by utilizing multiple cloud platforms or running multiple replicas of a Virtual Machine (VM) resulting into high operational cost. This paper has addressed this alarming problem from a different perspective by proposing a novel nline virtual machine ailure rediction and olerance odel (OFP-TM) with high availability awareness embedded in physical machines as well as virtual machines. The failure-prone VMs are estimated in real-time based on their future resource usage by developing an ensemble approach-based resource predictor. These VMs are assigned to a failure tolerance unit comprising of a resource provision matrix and Selection Box (S-Box) mechanism which triggers the migration of failure-prone VMs and handle any outage beforehand while maintaining the desired level of availability for cloud users. The proposed model is evaluated and compared against existing related approaches by simulating cloud environment and executing several experiments using a real-world workload Google Cluster dataset. Consequently, it has been concluded that OFP-TM improves availability and scales down the number of live VM migrations up to 33.5% and 83.3%, respectively, over without OFP-TM.
期刊介绍:
The Journal of Supercomputing publishes papers on the technology, architecture and systems, algorithms, languages and programs, performance measures and methods, and applications of all aspects of Supercomputing. Tutorial and survey papers are intended for workers and students in the fields associated with and employing advanced computer systems. The journal also publishes letters to the editor, especially in areas relating to policy, succinct statements of paradoxes, intuitively puzzling results, partial results and real needs.
Published theoretical and practical papers are advanced, in-depth treatments describing new developments and new ideas. Each includes an introduction summarizing prior, directly pertinent work that is useful for the reader to understand, in order to appreciate the advances being described.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
