{"title":"Association rule based similarity measures for the clustering of gene expression data.","authors":"Prerna Sethi, Sathya Alagiriswamy","doi":"10.2174/1874431101004010063","DOIUrl":null,"url":null,"abstract":"<p><p>In life threatening diseases, such as cancer, where the effective diagnosis includes annotation, early detection, distinction, and prediction, data mining and statistical approaches offer the promise for precise, accurate, and functionally robust analysis of gene expression data. The computational extraction of derived patterns from microarray gene expression is a non-trivial task that involves sophisticated algorithm design and analysis for specific domain discovery. In this paper, we have proposed a formal approach for feature extraction by first applying feature selection heuristics based on the statistical impurity measures, the Gini Index, Max Minority, and the Twoing Rule and obtaining the top 100-400 genes. We then analyze the associative dependencies between the genes and assign weights to the genes based on their degree of participation in the rules. Consequently, we present a weighted Jaccard and vector cosine similarity measure to compute the similarity between the discovered rules. Finally, we group the rules by applying hierarchical clustering. To demonstrate the usability and efficiency of the concept of our technique, we applied it to three publicly available, multiclass cancer gene expression datasets and performed a biomedical literature search to support the effectiveness of our results.</p>","PeriodicalId":88331,"journal":{"name":"The open medical informatics journal","volume":" ","pages":"63-73"},"PeriodicalIF":0.0000,"publicationDate":"2010-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.2174/1874431101004010063","citationCount":"16","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"The open medical informatics journal","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2174/1874431101004010063","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2010/5/28 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 16
Abstract
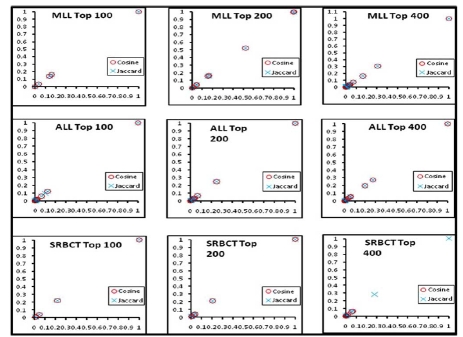
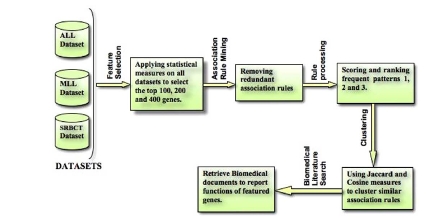
In life threatening diseases, such as cancer, where the effective diagnosis includes annotation, early detection, distinction, and prediction, data mining and statistical approaches offer the promise for precise, accurate, and functionally robust analysis of gene expression data. The computational extraction of derived patterns from microarray gene expression is a non-trivial task that involves sophisticated algorithm design and analysis for specific domain discovery. In this paper, we have proposed a formal approach for feature extraction by first applying feature selection heuristics based on the statistical impurity measures, the Gini Index, Max Minority, and the Twoing Rule and obtaining the top 100-400 genes. We then analyze the associative dependencies between the genes and assign weights to the genes based on their degree of participation in the rules. Consequently, we present a weighted Jaccard and vector cosine similarity measure to compute the similarity between the discovered rules. Finally, we group the rules by applying hierarchical clustering. To demonstrate the usability and efficiency of the concept of our technique, we applied it to three publicly available, multiclass cancer gene expression datasets and performed a biomedical literature search to support the effectiveness of our results.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
