Grzegorz Zycinski, Annalisa Barla, Margherita Squillario, Tiziana Sanavia, Barbara Di Camillo, Alessandro Verri
{"title":"Knowledge Driven Variable Selection (KDVS) - a new approach to enrichment analysis of gene signatures obtained from high-throughput data.","authors":"Grzegorz Zycinski, Annalisa Barla, Margherita Squillario, Tiziana Sanavia, Barbara Di Camillo, Alessandro Verri","doi":"10.1186/1751-0473-8-2","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>High-throughput (HT) technologies provide huge amount of gene expression data that can be used to identify biomarkers useful in the clinical practice. The most frequently used approaches first select a set of genes (i.e. gene signature) able to characterize differences between two or more phenotypical conditions, and then provide a functional assessment of the selected genes with an a posteriori enrichment analysis, based on biological knowledge. However, this approach comes with some drawbacks. First, gene selection procedure often requires tunable parameters that affect the outcome, typically producing many false hits. Second, a posteriori enrichment analysis is based on mapping between biological concepts and gene expression measurements, which is hard to compute because of constant changes in biological knowledge and genome analysis. Third, such mapping is typically used in the assessment of the coverage of gene signature by biological concepts, that is either score-based or requires tunable parameters as well, limiting its power.</p><p><strong>Results: </strong>We present Knowledge Driven Variable Selection (KDVS), a framework that uses a priori biological knowledge in HT data analysis. The expression data matrix is transformed, according to prior knowledge, into smaller matrices, easier to analyze and to interpret from both computational and biological viewpoints. Therefore KDVS, unlike most approaches, does not exclude a priori any function or process potentially relevant for the biological question under investigation. Differently from the standard approach where gene selection and functional assessment are applied independently, KDVS embeds these two steps into a unified statistical framework, decreasing the variability derived from the threshold-dependent selection, the mapping to the biological concepts, and the signature coverage. We present three case studies to assess the usefulness of the method.</p><p><strong>Conclusions: </strong>We showed that KDVS not only enables the selection of known biological functionalities with accuracy, but also identification of new ones. An efficient implementation of KDVS was devised to obtain results in a fast and robust way. Computing time is drastically reduced by the effective use of distributed resources. Finally, integrated visualization techniques immediately increase the interpretability of results. Overall, KDVS approach can be considered as a viable alternative to enrichment-based approaches.</p>","PeriodicalId":35052,"journal":{"name":"Source Code for Biology and Medicine","volume":" ","pages":"2"},"PeriodicalIF":0.0000,"publicationDate":"2013-01-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/1751-0473-8-2","citationCount":"7","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Source Code for Biology and Medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/1751-0473-8-2","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Decision Sciences","Score":null,"Total":0}
引用次数: 7
Abstract
Background: High-throughput (HT) technologies provide huge amount of gene expression data that can be used to identify biomarkers useful in the clinical practice. The most frequently used approaches first select a set of genes (i.e. gene signature) able to characterize differences between two or more phenotypical conditions, and then provide a functional assessment of the selected genes with an a posteriori enrichment analysis, based on biological knowledge. However, this approach comes with some drawbacks. First, gene selection procedure often requires tunable parameters that affect the outcome, typically producing many false hits. Second, a posteriori enrichment analysis is based on mapping between biological concepts and gene expression measurements, which is hard to compute because of constant changes in biological knowledge and genome analysis. Third, such mapping is typically used in the assessment of the coverage of gene signature by biological concepts, that is either score-based or requires tunable parameters as well, limiting its power.
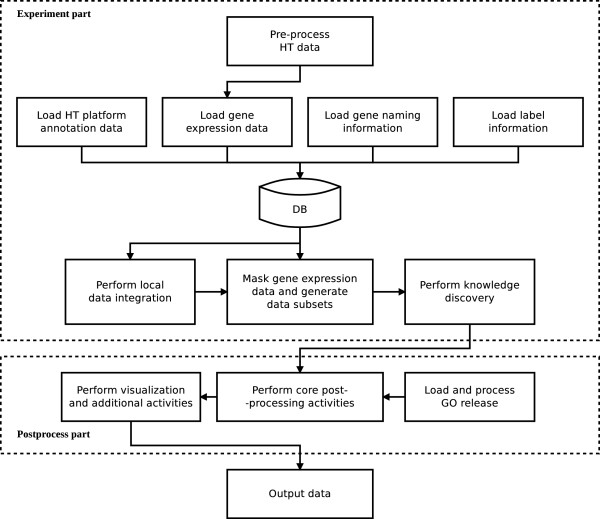
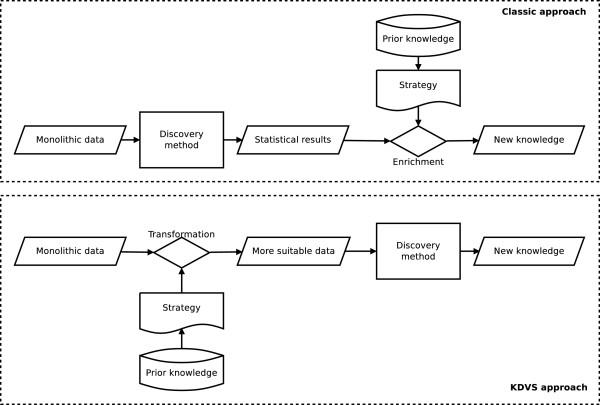
Results: We present Knowledge Driven Variable Selection (KDVS), a framework that uses a priori biological knowledge in HT data analysis. The expression data matrix is transformed, according to prior knowledge, into smaller matrices, easier to analyze and to interpret from both computational and biological viewpoints. Therefore KDVS, unlike most approaches, does not exclude a priori any function or process potentially relevant for the biological question under investigation. Differently from the standard approach where gene selection and functional assessment are applied independently, KDVS embeds these two steps into a unified statistical framework, decreasing the variability derived from the threshold-dependent selection, the mapping to the biological concepts, and the signature coverage. We present three case studies to assess the usefulness of the method.
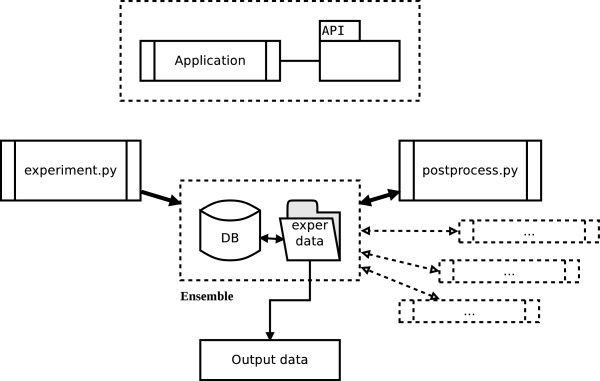
Conclusions: We showed that KDVS not only enables the selection of known biological functionalities with accuracy, but also identification of new ones. An efficient implementation of KDVS was devised to obtain results in a fast and robust way. Computing time is drastically reduced by the effective use of distributed resources. Finally, integrated visualization techniques immediately increase the interpretability of results. Overall, KDVS approach can be considered as a viable alternative to enrichment-based approaches.
期刊介绍:
Source Code for Biology and Medicine is a peer-reviewed open access, online journal that publishes articles on source code employed over a wide range of applications in biology and medicine. The journal"s aim is to publish source code for distribution and use in the public domain in order to advance biological and medical research. Through this dissemination, it may be possible to shorten the time required for solving certain computational problems for which there is limited source code availability or resources.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
