{"title":"A General Iterative Clustering Algorithm.","authors":"Ziqiang Lin, Eugene Laska, Carole Siegel","doi":"10.1002/sam.11573","DOIUrl":null,"url":null,"abstract":"<p><p>The quality of a cluster analysis of unlabeled units depends on the quality of the between units dissimilarity measures. Data dependent dissimilarity is more objective than data independent geometric measures such as Euclidean distance. As suggested by Breiman, many data driven approaches are based on decision tree ensembles, such as a random forest (RF), that produce a proximity matrix that can easily be transformed into a dissimilarity matrix. A RF can be obtained using labels that distinguish units with real data from units with synthetic data. The resulting dissimilarity matrix is input to a clustering program and units are assigned labels corresponding to cluster membership. We introduce a General Iterative Cluster (GIC) algorithm that improves the proximity matrix and clusters of the base RF. The cluster labels are used to grow a new RF yielding an updated proximity matrix which is entered into the clustering program. The process is repeated until convergence. The same procedure can be used with many base procedures such as the Extremely Randomized Tree ensemble. We evaluate the performance of the GIC algorithm using benchmark and simulated data sets. The properties measured by the Silhouette Score are substantially superior to the base clustering algorithm. The GIC package has been released in R: https://cran.r-project.org/web/packages/GIC/index.html.</p>","PeriodicalId":48684,"journal":{"name":"Statistical Analysis and Data Mining","volume":"15 4","pages":"433-446"},"PeriodicalIF":3.6000,"publicationDate":"2022-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/c8/08/SAM-15-433.PMC9438941.pdf","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Statistical Analysis and Data Mining","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1002/sam.11573","RegionNum":4,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/1/31 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 1
Abstract
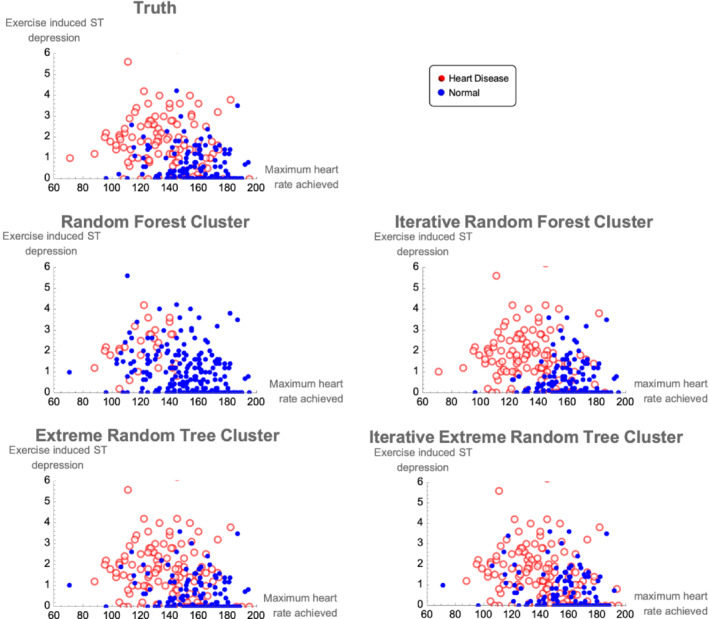
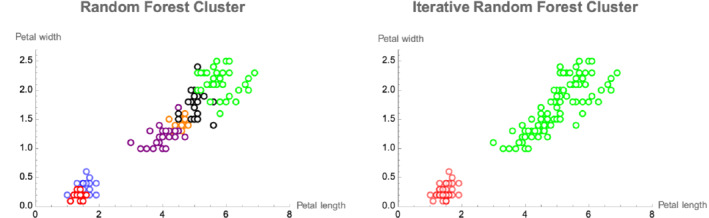
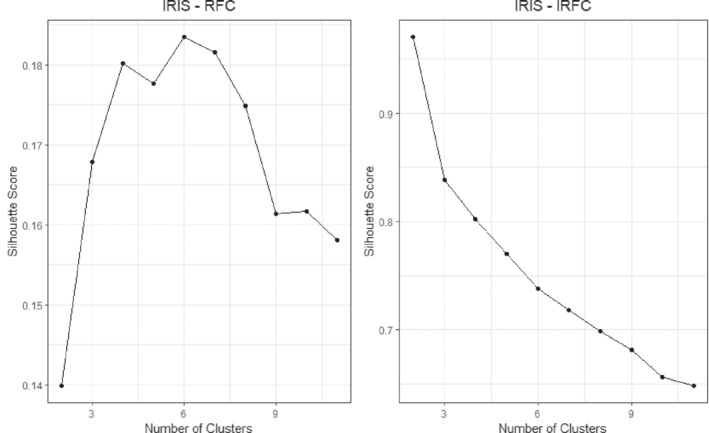
The quality of a cluster analysis of unlabeled units depends on the quality of the between units dissimilarity measures. Data dependent dissimilarity is more objective than data independent geometric measures such as Euclidean distance. As suggested by Breiman, many data driven approaches are based on decision tree ensembles, such as a random forest (RF), that produce a proximity matrix that can easily be transformed into a dissimilarity matrix. A RF can be obtained using labels that distinguish units with real data from units with synthetic data. The resulting dissimilarity matrix is input to a clustering program and units are assigned labels corresponding to cluster membership. We introduce a General Iterative Cluster (GIC) algorithm that improves the proximity matrix and clusters of the base RF. The cluster labels are used to grow a new RF yielding an updated proximity matrix which is entered into the clustering program. The process is repeated until convergence. The same procedure can be used with many base procedures such as the Extremely Randomized Tree ensemble. We evaluate the performance of the GIC algorithm using benchmark and simulated data sets. The properties measured by the Silhouette Score are substantially superior to the base clustering algorithm. The GIC package has been released in R: https://cran.r-project.org/web/packages/GIC/index.html.
期刊介绍:
Statistical Analysis and Data Mining addresses the broad area of data analysis, including statistical approaches, machine learning, data mining, and applications. Topics include statistical and computational approaches for analyzing massive and complex datasets, novel statistical and/or machine learning methods and theory, and state-of-the-art applications with high impact. Of special interest are articles that describe innovative analytical techniques, and discuss their application to real problems, in such a way that they are accessible and beneficial to domain experts across science, engineering, and commerce.
The focus of the journal is on papers which satisfy one or more of the following criteria:
Solve data analysis problems associated with massive, complex datasets
Develop innovative statistical approaches, machine learning algorithms, or methods integrating ideas across disciplines, e.g., statistics, computer science, electrical engineering, operation research.
Formulate and solve high-impact real-world problems which challenge existing paradigms via new statistical and/or computational models
Provide survey to prominent research topics.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
